
В Международный Женский День 8 марта к нам обратилась одна из крупных организаций города Бишкека с отказавшим RAID-массивом. Массив из 11 SAS-дисков емкостью 900 Гбайт каждый, и в дополнение — двенадцатый диск горячей замены (hot spare). На 11 дисках был собран RAID-5 (странно, но, как говорится, выбор сисадмина священен). Массив перестал работать в ночь на 7 марта, обслуживающий его персонал ожидал сутки в надежде на то, что тот поднимется сам, но чуда не случилось. Массив остался неисправен, так как для запуска ребилда в нем банально уже не хватало участников.
Предстояло выяснить следующее:
- Порядок, в котором «уходили» и «приходили» диски массива, поскольку в полке (а массив физически был собран в стандартном blade-server) имелся диск горячей замены.
- Последнюю рабочую конфигурацию массива.
- Причину выхода массива из строя.
Основная конфигурация массива, к счастью, оказалась доступной через управляющее приложение RAID. Поэтому с размером страйпа (порции данных в секторах, распределяемой по дискам), типом массива и некоторыми другими характеристиками все было ясно исходно. Проблему составлял только состав массива: какие именно диски исключались, какие включались в его состав, и в каком составе он окончательно вышел из строя.

Работу начали с поиска метаданных массива. Современные дисковые массивы, собранные на серьезных контроллерах, часто несут массу служебной информации, необходимой для функционирования RAID, прямо на дисках. Эта информация может быть как зашифрованной, так и находиться на дисках в открытом виде. Но, в любом случае, она исключительно полезна и должна использоваться в работе по восстановлению данных.
В нашем случае эта информация оказалась частично открытой, частично ее пришлось расшифровывать. Порядок дисков в метаданных хранился в открытом виде, по серийным номерам; статус дисков (активный, не активный, горячая замена) был зашифрован битовыми флагами.
На основании метаданных удалось выяснить, что массив относительно недавно пережил ребилд: из массива был исключен один из дисков, и на его место встал диск горячей замены. Ребилд завершился успешно, и массив продолжил свою работу.
После этого из массива «ушел» еще один диск. С этого момента массив начал работать в весьма рискованном для данных состоянии degraded (деградирован). Что это означает?
RAID-5 — это дисковые массивы с контролем четности, допускающие потерю одного участника массива. При этом блоки четности (XOR-блоки) распределяются на всех дисках массива по определенному алгоритму, как правило — равномерно. Если один из дисков массива исчезает (по любой причине — например, ломается), данные с этого диска восстанавливаются по блокам четности контроллером массива, и массив продолжает работать. Если в массиве предусмотрен диск горячей замены, контроллер включит его в состав массива, при этом будет запущена процедура ребилда — восстановления содержимого исключенного члена массива на основании блоков четности с других дисков.
Однако если диска горячей замены нет, массив начинает работать в деградированном состоянии. Это означает, что исключенный из массива диск воссоздается контроллером на основании блоков четности с остальных дисков, но запаса прочности у массива уже нет — если выйдет из строя еще хотя бы один диск, контроллеру не хватит информации из блоков четности для воссоздания потерянных дисков, целостность данных нарушится, и массив перестанет существовать — контроллер должен будет перевести его в состояние offline.
В нашем случае в массив включался один диск, а исключалось из него три. Для корректного восстановления информации требовалось определить, вместо какого диска встал в массив накопитель горячей замены (таким образом определялось, какой диск покинул массив первым); затем следовало определить, какой из двух оставшихся исключенных накопителей был исключен раньше.
С диском горячей замены проблем не было: он оказался в метаданных массива, ведь он был включен в него штатно и, следовательно, был также штатно прописан в метаданные. По его положению в массиве мы определили, какой из исходных дисков был исключен из массива первым. Этот диск был исключен и из анализа.
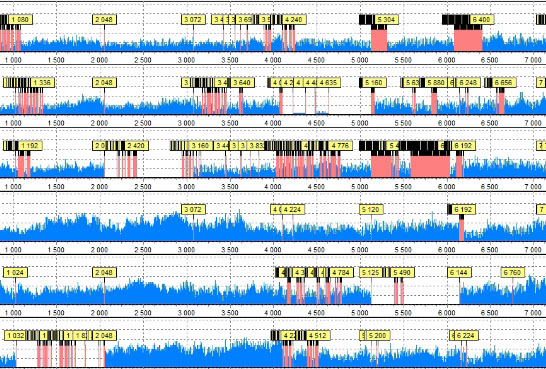

Для определения наиболее актуального участника массива мы воспользовались наиболее достоверным методом — анализом энтропии. Разные инструменты представляют энтропию данных по разному. В спорных случаях оптимальнее всего использовать несколько методов визуализации энтропии, так как традиционный «плоский» метод может оказаться малоинформативен. Наш случай оказался как раз таким, спорным — так как исключение дисков из массива происходило в течение небольшого времени.
Поэтому, кроме традиционного «плоского» метода визуализации энтропии (гистограммы), мы использовали также трехмерную визуализацию, дающую гораздо более детальную картину распределения данных внутри анализируемого объекта. Результат: менее актуальный диск определен, диски выстроены в массиве в правильном порядке, массив собран и данные доступны.
Данный массив, ввиду того, что все диски массива оказались исправны, был собран нами по цене копирования, по акции «соберем RAID по цене копирования».














