В Международный Женский День 8 марта к нам обратилась одна из крупных организаций города Бишкека с отказавшим RAID-массивом. Массив из 11 SAS-дисков емкостью 900 Гбайт каждый, и в дополнение — двенадцатый диск горячей замены (hot spare). На 11 дисках был собран RAID-5 (странно, но, как говорится, выбор сисадмина священен). Массив перестал работать в ночь на 7 марта, обслуживающий его персонал ожидал сутки в надежде на то, что тот поднимется сам, но чуда не случилось. Массив остался неисправен, так как для запуска ребилда в нем банально уже не хватало участников.
Предстояло выяснить следующее:
Порядок, в котором «уходили» и «приходили» диски массива, поскольку в полке (а массив физически был собран в стандартном blade-server) имелся диск горячей замены.
Последнюю рабочую конфигурацию массива.
Причину выхода массива из строя.
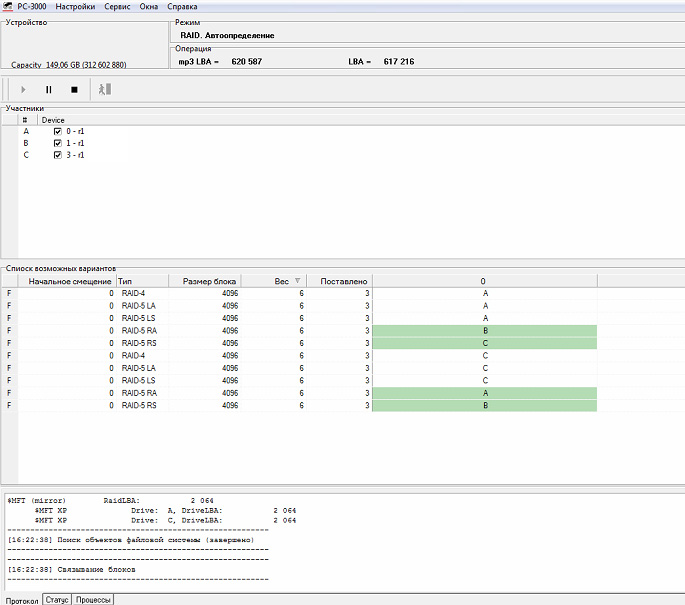
Основная конфигурация массива, к счастью, оказалась доступной через управляющее приложение RAID. Поэтому с размером страйпа (порции данных в секторах, распределяемой по дискам), типом массива и некоторыми другими характеристиками все было ясно исходно. Проблему составлял только состав массива: какие именно диски исключались, какие включались в его состав, и в каком составе он окончательно вышел из строя.
Этикетка сервера.
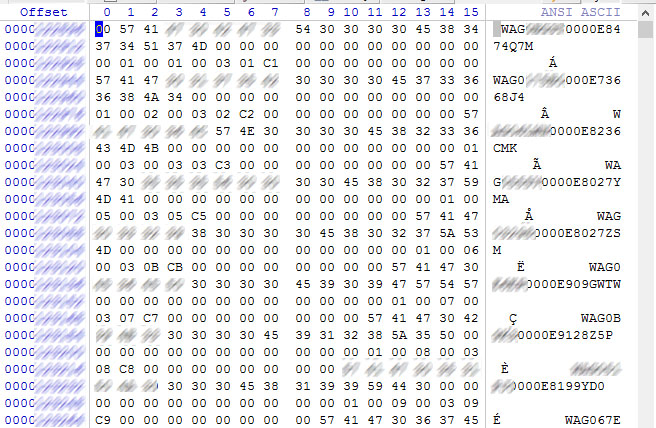
Работу начали с поиска метаданных массива. Современные дисковые массивы, собранные на серьезных контроллерах, часто несут массу служебной информации, необходимой для функционирования RAID, прямо на дисках. Эта информация может быть как зашифрованной, так и находиться на дисках в открытом виде. Но, в любом случае, она исключительно полезна и должна использоваться в работе по восстановлению данных.
В нашем случае эта информация оказалась частично открытой, частично ее пришлось расшифровывать. Порядок дисков в метаданных хранился в открытом виде, по серийным номерам; статус дисков (активный, не активный, горячая замена) был зашифрован битовыми флагами.
На основании метаданных удалось выяснить, что массив относительно недавно пережил ребилд: из массива был исключен один из дисков, и на его место встал диск горячей замены. Ребилд завершился успешно, и массив продолжил свою работу.
После этого из массива «ушел» еще один диск. С этого момента массив начал работать в весьма рискованном для данных состоянии degraded (деградирован). Что это означает?
RAID-5 — это дисковые массивы с контролем четности, допускающие потерю одного участника массива. При этом блоки четности (XOR-блоки) распределяются на всех дисках массива по определенному алгоритму, как правило — равномерно. Если один из дисков массива исчезает (по любой причине — например, ломается), данные с этого диска восстанавливаются по блокам четности контроллером массива, и массив продолжает работать. Если в массиве предусмотрен диск горячей замены, контроллер включит его в состав массива, при этом будет запущена процедура ребилда — восстановления содержимого исключенного члена массива на основании блоков четности с других дисков.
Однако если диска горячей замены нет, массив начинает работать в деградированном состоянии. Это означает, что исключенный из массива диск воссоздается контроллером на основании блоков четности с остальных дисков, но запаса прочности у массива уже нет — если выйдет из строя еще хотя бы один диск, контроллеру не хватит информации из блоков четности для воссоздания потерянных дисков, целостность данных нарушится, и массив перестанет существовать — контроллер должен будет перевести его в состояние offline.
Фрагмент метаданных поступившего в работу массива
В нашем случае в массив включался один диск, а исключалось из него три. Для корректного восстановления информации требовалось определить, вместо какого диска встал в массив накопитель горячей замены (таким образом определялось, какой диск покинул массив первым); затем следовало определить, какой из двух оставшихся исключенных накопителей был исключен раньше.
С диском горячей замены проблем не было: он оказался в метаданных массива, ведь он был включен в него штатно и, следовательно, был также штатно прописан в метаданные. По его положению в массиве мы определили, какой из исходных дисков был исключен из массива первым. Этот диск был исключен и из анализа.
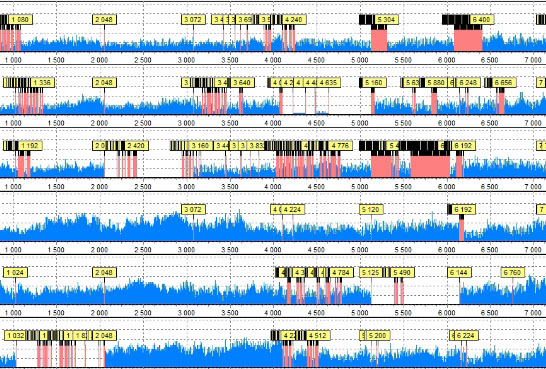
Статистика (включая карту энтропий) участников массива, фрагмент.
Трехмерная визуализация энтропии одного из дисков массива, в двух разных проекциях.
Для определения наиболее актуального участника массива мы воспользовались наиболее достоверным методом — анализом энтропии. Разные инструменты представляют энтропию данных по разному. В спорных случаях оптимальнее всего использовать несколько методов визуализации энтропии, так как традиционный «плоский» метод может оказаться малоинформативен. Наш случай оказался как раз таким, спорным — так как исключение дисков из массива происходило в течение небольшого времени.
Поэтому, кроме традиционного «плоского» метода визуализации энтропии (гистограммы), мы использовали также трехмерную визуализацию, дающую гораздо более детальную картину распределения данных внутри анализируемого объекта. Результат: менее актуальный диск определен, диски выстроены в массиве в правильном порядке, массив собран и данные доступны.
Данный массив, ввиду того, что все диски массива оказались исправны, был собран нами по цене копирования, по акции «соберем RAID по цене копирования».
Задача. Экстренно восстановить данные с дискового массива RAID-5
Описание проблемы. Массив поступил в виде дисков (не в составе сервера), без какой-либо нумерации или пометок. Массив вышел из строя в результате аварийного отключения питания. Тип интерфейса: SAS.
Результаты диагностики Диагностировано, что все диски массива исправны. Скорее всего, неисправен контроллер массива, но он не был нам предоставлен. Принято решение собирать массив программными средствами.
Необходимые для восстановления информации процедуры.
1) Определение конфигурации массива.
2) Сборка массива.
3) Извлечение пользовательских данных.
Результат.
Данные восстановлены полностью.
Особенности массива.
Поскольку данные с данного массива требуются экстра-срочно, сами диски исправны, заказчиком было принято решение для экономии времени не производить процедуру обязательного создания резервных копий дисков. Работы велись на дисках заказчика, подключенных к системе в режиме «read only».
Задача. Восстановить данные с дискового массива RAID-5
Описание проблемы. Массив поступил в degraded состоянии, в работу поступило 3 диска (один физически неисправен), каждый емкостью 80 Гб, тип интерфейса: SATA.
Результаты диагностики В целях диагностики по стандартной методике проверялся каждый диск. Выяснено, что в массиве вышел из строя один диск, массив перешел в состояние degraded (деградирован; массив может работать, но при выходе из строя следующего диска выйдет из строя). Накопители массива старые, медленные, поэтому в деградированном состоянии массив очень медленно работает.
Необходимые для восстановления информации процедуры.
1) Создание полной посекторной копии каждого накопителя.
2) Определение конфигурации массива.
3) Сборка массива.
4) Извлечение пользовательских данных.
Результат.
Данные восстановлены полностью.
Особенности массива.
Массив имеет солидный возраст, составляющие его диски — также. Благодаря этому скорость массива при выпадении одного диска заметно упала; заказчик решил, что массив неисправен, так как копирование данных (данные заказчика — несколько миллионов файлов размером в несколько байт каждый) оценивалось системой в несколько лет. Для ускорения выливки данных массив был собран с использованием Data Extractor RAID Edition после создания посекторных копий участников массива на SSD-диске; выливка данных также производилась на твердотельный накопитель новейшего форм-фактора NMVe для ускорения процесса (первое) и для ускорения работы системы у нашего заказчика (второе, и главное).
RAID – технология старая, проверенная временем и надежная. RAID – аббревиатура, означающая Rebundant Array of Independent Drives (Избыточный массив независимых дисков). Что это значит? Если объяснять просто, то это такое устройство, которое объединяет в один диск несколько дисков, и объединяет по-разному. Но результат всегда одинаковый: для пользователя это будет единый накопитель, на который он может скопировать свои файлы.
Хорошо, спросите вы, а зачем тогда нужен этот самый RAID, если можно с таким же успехом просто подключить жесткий диск? Естественно, раз он был придуман, то не просто так. Какие задачи решает дисковый массив?
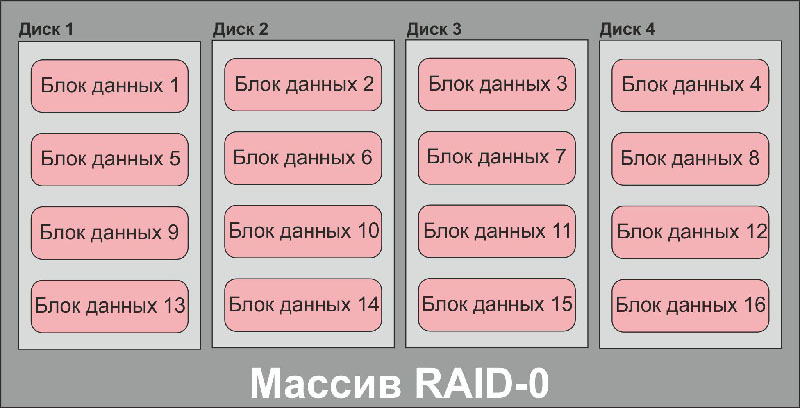
Дисковый массив из 8 дисков Western Digital Red емкостью 3 ТБ каждый. RAIR-0, общая емкость массива 24 ТБ
Основные функции дисковых массивов
Первая – это повышение производительности. Организация нескольких дисков в единое устройство хранения информации позволяет записывать данные пользователя одновременно на все диски массива порциями, тем самым увеличивая (в теории) скорость работы дисковой подсистемы кратно количеству дисков в ней. На практике, конечно, прирост производительности не кратен числу дисков, но все равно, он весьма высок и превышает обычные для стандартных жестких дисков скорости как минимум на 50%.
Вторая – это повышение емкости. Несколько дисков, объединенных в массив, будут иметь или суммарную емкость всех дисков массива, или немногим менее (обычно суммарная емкость всех дисков минус емкость одного или двух дисков).
Третья – это повышение надежности. Неспроста в расшифровке аббревиатуры RAID присутствует слово «избыточность» — большинство типов дисковых массивов реализуют те или иные механизмы защиты данных от потерь. Единственный тип RAID, в котором не реализована избыточность – это RAID-0, или, как его еще называют, «страйп». Этот тип массива использует все диски для хранения пользовательских данных, он самый быстрый из всех типов дисковых массивов и позволяет получить самую большую конечную емкость устройства, но при этом он абсолютно не защищен от сбоев, и в случае любой неисправности любого члена массива RAID-0 данные на нем теряются.
Как это работает? В целом просто, как и все гениальное.
Диски разделяются на блоки, а блоки чередуются в определенном порядке. Когда нужно записать информацию, контроллер распределяет ее по свободным блокам. Вот и все. Казалось бы, что может быть надежнее?
Типы дисковых массивов
Сохранение общего принципа «блочная запись данных в определенном порядке» порождает массу его разновидностей. Можно записывать данные блоками с чередованием на каждом диске, через диск, через несколько дисков; можно записывать информацию блоками разной величины; можно разделить блоки на блоки с данными и блоки с информацией для восстановления (избыточность), и также чередовать их по-разному. В общем, вариантов масса. Это и порождает основные проблемы восстановления данных с дисковых массивов.
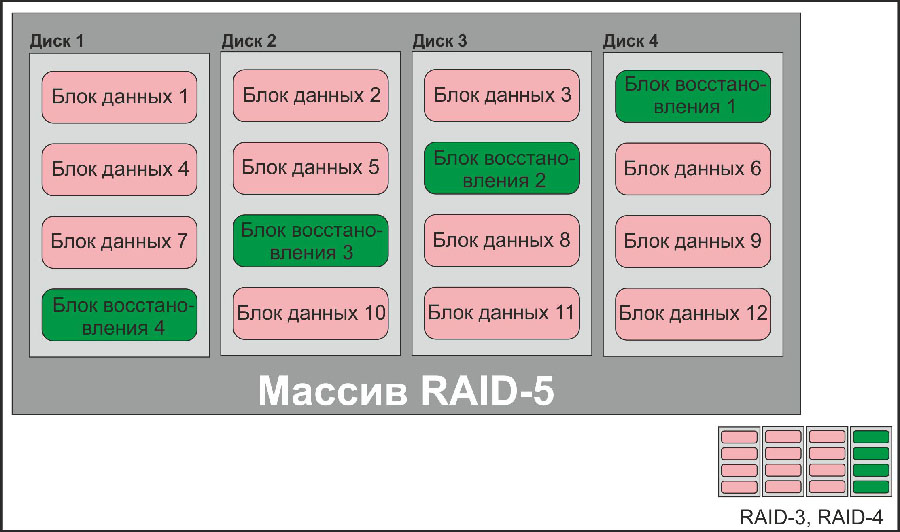
Всем известно, что RAID-массивы бывают разными: RAID-0 (страйп), RAID-1 (зеркало), RAID-3, RAID-4 (массивы с контролем четности, вынесенным на отдельный диск), RAID-5, RAID-6 (массивы с контролем четности блочного типа). Мы не будем описывать эти типы дисковых массивов – в интернете об этом информации более чем достаточно; на рисунках ниже изображено, как они работают.
Блок-схема дискового массива типа RAID-0
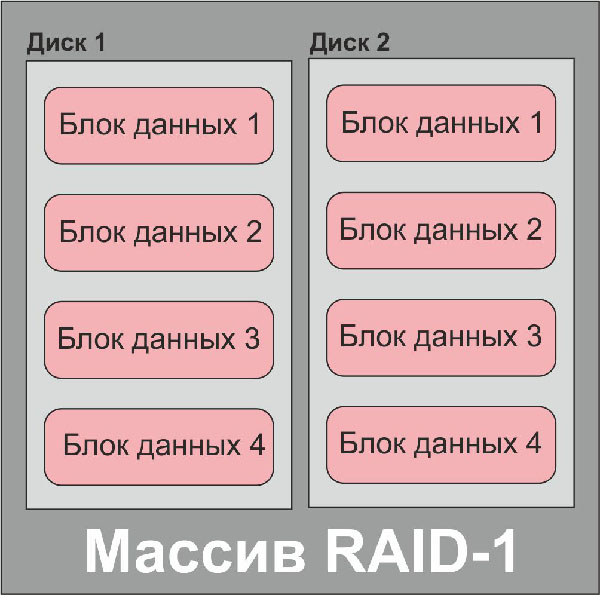
Блок-схема дискового массива типа RAID-1
Блок-схема дискового массива типа RAID-5, с объяснением типов массивов RAID-3 и RAID-4
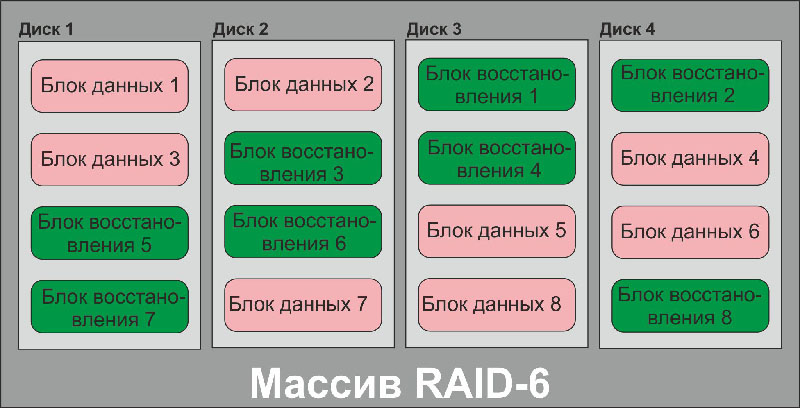
Блок-схема дискового массива типа RAID-6
Реализация избыточности: XOR и коды Рида-Соломона
Намного интереснее то, как реализуется избыточность. Для этого используется два логических механизма: XOR (RAID-3, RAID-4, RAID-5) и XOR + код Рида-Соломона (RAID-6).
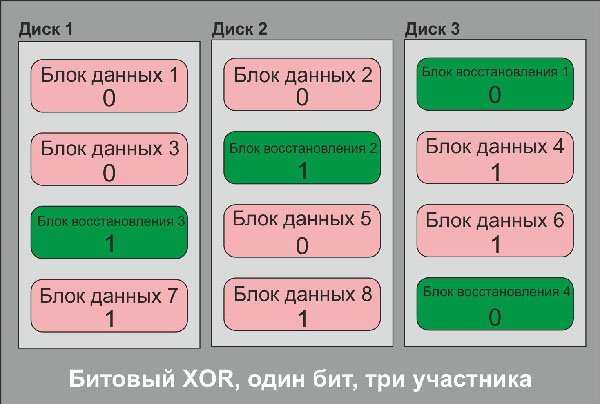
Что такое XOR? Это логический оператор, который принято обозначать как «исключающее или». Работает он просто и начинает иметь смысл при трех участниках оператора: первом слагаемом, втором слагаемом и результате. Смысл оператора заключается в том, что зная два из трех его участников мы всегда можем точно назвать третий. Конечно, XOR можно организовать и для четырех, и для пяти, и для большего количества участников – просто сами операции восстановления недостающего члена ряда будут сложнее. Как это работает? Давайте рассмотрим на примере ряда из трех членов (пусть для простоты это будет три диска с однобитовым размером блока, чтобы нам было проще представить механизм):
XOR-матрица для трех участников по одному биту каждый
Схема восстановления утерянного участника при помощи XOR-матрицы
Мы видим, что при утере любого из дисков содержимое утерянного байта в каждом блоке утерянного диска может быть восстановлено из двух других с использованием операции «исключающее или». Очевидно, что при потере одного диска, основанного на этом принципе восстановления (избыточности), массив продолжит работать нормально, хотя и медленнее обычного, так как много времени будет тратиться контроллером массива на расчет недостающих битов информации. По этой причине дисковые массивы с избыточностью обычно делаются с небольшим размером блока (до 256 секторов), так как пересчет больших блоков слишком сильно нагружает контроллер и общая производительность массива при больших блоках падает просто катастрофически; кроме того, активное использование контроллера в режиме постоянного пересчета данных неизбежно приведет к его повышенному износу и по этой причине – преждевременному выходу из строя.
Более высокий уровень надежности дискового массива можно обеспечить, только реализовав дополнительный механизм восстановления утерянных данных. Такой механизм был реализован в массивах RAID-6, он позволяет массиву пережить потерю сразу двух дисков, и минимальное количество членов массива, соответственно, будет четыре. Основан этот механизм на использовании двух независимых систем пересчета данных: XOR (о нем мы сказали выше) и коды Рида-Соломона. В массивах типа RAID-6 чередуются блоки данных, блоки XOR и блоки кодов Рида-Соломона так, что при выходе из строя одного или даже двух дисков содержимое этих дисков может быть пересчитано контроллером, и массив продолжит работать (данные будут доступны). Что же такое коды Рида-Соломона?
Если говорить максимально просто, то код Рида-Соломона – это битовая матрица, позволяющая при утере одного или двух ее участников рассчитать их содержимое по остальным. Казалось бы, чем отличается код Рида-Соломона от XOR? Отличие в том, что коды Рида-Соломона позволяют восстановить битовое значение при отсутствии не одного, а двух компонентов. Для этого используются более сложные алгоритмы: поля Галуа, синдром ошибки и прямое преобразование Фурье. Если при использовании XOR восстановление возможно только при сохранении цикличности расположения битов информации, то при использовании кодов Рида-Соломона сохранение цикличности уже не требуется, так как математика контроллера сама способна рассчитать положение ошибок и скорректировать их.
Естественно, использование такого сложного алгоритма восстановления данных приведет, в случае утери одного или двух дисков из массива RAID-6, к сильному износу контроллера и, как следствие, к его преждевременному выходу из строя.
Состояние массива с избыточностью: нормальное, деградировавшее, неисправное
Любой дисковый массив, имеющий избыточность, по своему состоянию разделяется на нормально работающий (все диски массива исправны и массив функционирует нормально, данные защищены), деградировавший (degraded) (один или два (в зависимости от типа RAID) диска массива неисправны, массив функционирует с пересчетом отсутствующих дисков, данные не защищены) и неисправный (вышло из строя больше дисков, чем поддерживает избыточность, контроллер не имеет возможности рассчитать данные на вышедших из строя дисках, массив перестал существовать как устройство хранения информации).
Нормально работающий массив – его естественное состояние. Для того, чтобы не потерять массив в случае выхода из строя одного из его членов, было внедрено понятие «горячая замена» (hot spare) – пустой диск, единственная функция которого – принять на себя пересчитанные контроллером данные вышедшего из строя накопителя. Такой диск после переноса на него рассчитанных данных включается в массив, а вышедший из строя диск из него исключается. Эта процедура называется «перестроить массив» (RAID rebuild). Как правило, во время перестройки (ребилда) массив работает значительно медленнее, чем в нормальном состоянии. По этой причине в случае ребилда деградировавшего массива пользователь может его перезагрузить («что-то зависает, надо перезапустить»). Результатом такой перезагрузки может стать переход массива из состояния «деградировавший» в состояние «неисправный». Во избежание подобных последствий, при наличии настроенного диска горячей замены, в случае значительной потери производительности массива зайдите в утилиту его настройки и мониторинга и посмотрите, чем именно сейчас занят массив. Если он покажет вам процесс rebuild – не трогайте массив до его окончания.
Состояние массива без избыточности: исправен и неисправен
Для массивов без избыточности (RAID-0 и RAID-1) возможно только два состояния: массив исправен (все диски массива работают и данные доступны) и массив неисправен (один или несколько дисков массива вышли из строя, данные недоступны).
Если с массивами RAID-0 выход одного или нескольких участников массива из строя приводит к образованию «дыр» в данных (те места, где должны быть блоки данных из вышедших из строя носителей), то с массивами RAID-1 (зеркало) все намного интереснее. По простой логике зеркало, или массив с полным дублированием диска, не должно приводить к потере данных в случае выхода из строя одного из участников. На практике это так далеко не всегда. Довольно часто (особенно в случае использования в массиве дисков одного производителя и одной модели) один диск «клонирует» не только данные со второго, но и его ошибки, что может привести к одновременному выходу из строя обоих дисков с идентичными симптомами. В настоящее время зеркалирование – уже отмирающая технология, предпочтение отдается блочным массивам с избыточностью как более надежным.
Составные массивы. Кластеры. Локусы. Современные системы хранения данных
Конечно же, свет вовсе не сошелся клином на тех типах RAID, которые мы перечислили выше; производители всевозможных устройств с удовольствием применяют различные алгоритмы, комбинации и решения для реализации наиболее (по их мнению) быстрых и надежным типов массивов. Один из методов «улучшения» RAID – применение технологий составных массивов.
В самом простом случае составной дисковый массив – это два или больше массива, объединенных в один. Например, два RAID-5, которые объединены в зеркало (RAID-1). Или два страйпа (RAID-0), объединенных в зеркало. И т.п. По типу объединения такие массивы обычно имеют двойную цифровую кодировку (RAID50 или RAID5+0, RAID10 или RAID1+0, и т.д.). Составление массива из нескольких добавляет массиву надежности.
Более сложные структуры создаются уже для промышленных систем хранения данных, они призваны обеспечить большие емкости при высоком уровне отказоустойчивости. Как правило, это составные массивы иерархического типа, реализованные по принципу матрешки: более мелкие массивы помещаются в более крупные, и так до тех пор, пока на верхушке не остается один, наиболее крупный, RAID. Например, такая структура:
Десять массивов RAID-5, объединены попарно в массивы RAID-0 (таких массивов получается пять), эти массивы RAID-0 объединены в RAID-6; четыре таких массива RAID-6 объединены в RAID-0. Как разграничить такую схему?
Для этого придумана специальная терминология.
Промышленное устройство хранения информации (или просто дисковый массив) – это окончательный продукт взаимодействия всех дисков в системе, то свободное место, которое он предоставляет для использования.
Кластер – первичная ячейка хранения данных, объединение нескольких массивов первого или второго уровня (в нашем примере кластером является попарное объединение массивов RAID-5 в массив RAID-0).
Локус – объединение кластеров.
Таким образом, простым определением промышленного устройства хранения информации будет: промышленное устройство хранения информации – это иерархическое объединение в единое дисковое поле локусов кластеризованных дисковых субъединиц.
Физическая реализация дисковых массивов
Как дисковые массивы реализуются на практике? Возможно два метода: программный и аппаратный.
Массив на программном уровне может быть создан даже на базе одного диска (в RAID программно собираются участки его поверхности). Обычно программный массив собирается в Linux, реже – Mac или Windows. Инструменты создания программных массивов в Linux/Unix системах намного мощнее, удобнее и гибче, чем в Windows, поэтому в подавляющем большинстве NAS (Network Attached Storage) для сборки массива используется Linux. Соответственно, собирая программный массив блочного типа с избыточностью, нужно быть готовым к тому, что он будет «отъедать» часть ресурсов процессора и оперативной памяти для обсчета избыточности.
Массив на аппаратном уровне собирается с использованием специализированного RAID-контроллера – это или внешняя карта расширения, устанавливаемая в PCI или PCI-E слот, или интегрированный в материнскую плату микрочип. В любом случае, всю математику, а также хранение настроек, логов ошибок и т.п., берет на себя уже не программная часть, реализванная в операционной системе, и не ресурсы компьютера, а аппаратная часть контроллера.
В большинстве случаев для организации дискового массива требуются диски одинакового объема. Однако некоторые контроллеры позволяют реализовывать блочные дисковые массивы с избыточностью и на дисках разного объема: DROBO, Synology и т.п. Такие массивы строятся на принципе разделения общего дискового пространства на зоны, из которых собирается конечный массив. Эти массивы имеют свои собственные маркетинговые названия (например, Beyond RAID у DROBO, Hybrid RAID у Synology, и т.п.), однако суть всегда остается одинаковой: это, во-первых, блочный массив, а во-вторых, у него имеется реализованная циклическим способом избыточность.
На каких дисках строятся дисковые массивы
В принципе для построения массива нет ограничений по используемым носителям. Это могут быть и традиционные жесткие диски с любым интерфейсом (SCSI, SAS, SATA, PATA), и твердотельные диски с любым интерфейсом (SATA, NVMe, M.2 и т.п.), и карты памяти (в китае даже выпускаются особые платы расширения, позволяющие сделать из нескольких карт SD один твердотельный накопитель – при этом карты памяти работают как RAID-0).
Массивы на SSD собираются в дата-центрах, для которых приоритетным является не объем хранилища, а его производительность – например, там, где требуется обрабатывать медиа-контент (видео в разрешении 4К и 8К, фотографии, снятые камерами с разрешением больше 32 мегапикселей, и т.п.). Это киностудии, медиахранилища (например, облако iCloud) и т.п.
На жестких дисках собираются массивы тогда, когда объем важнее производительности – и, естественно, когда построить массив на SSD не позволяет бюджет (твердотельные диски намного дороже жестких). Массивы на SATA или PATA-дисках (последние уже почти не встречаются) собираются в бюджетном сегменте, они дешевле всех других и позволяют строить хранилища довольно внушительного объема.
SCSI или SAS диски используются в бизнес- или enterprise-решениях, их отличает более высокая степень надежности, чем SATA/PATA диски. Кроме того, обычно SCSI/SAS диски разрабатываются именно для использования в серверах, поэтому их отличает (обычно) более высокая скорость вращения шпинделя, уменьшенное время поиска информации, высокие скорости передачи данных.
Массивы на картах памяти строят в подавляющем большинстве случаев обычные пользователи, хотя такие массивы могут быть реализованы в некоторых профессиональных камерах для повышения безопасности данных (две карты памяти, которые работают в режиме RAID-1). Массив на картах памяти наименее надежен, так как качество карт памяти значительно уступает качеству жестких или твердотельных дисков, карты памяти имеют гораздо больше шансов на выход из строя и, наконец, они просто значительно медленнее дисковых накопителей.
Восстановление дисковых массивов в компании IT-Doctor
Наш опыт в области восстановления данных составляет более 25 лет, и немалую часть этого времени мы посвятили дисковым массивам. Основная часть наших клиентов обращалась с устройствами NAS и с внешними USB-дисками, оборудованными внутри 2 – 4 накопителями. Как правило, в таких устройствах реализуется либо массив RAID-0, либо RAID-5. Подобного рода массивы восстанавливаются обычно очень быстро, так как нами накоплена большая база стандартных конфигураций дисковых массивов для такого рода устройств. В 90% случаев при исправных дисках при обращении к нам с устройством NAS или внешним диском, построенным по архитектуре RAID, мы восстановим данные в тот же или на следующий день.
В более сложных случаях, когда применяется нетривиальная конфигурация массива, или когда один или несколько дисков в массиве вышли из строя в разное время, и требуется определить, какой из них несет актуальные данные, а какой следует игнорировать, процесс восстановления данных может занять 2 – 3 дня. С чем это связано?
Прежде всего, мы обязательно сделаем посекторную копию каждого диска массива. Это делается даже в том случае, если все диски в массиве исправны. Работа с копией полностью исключает фатальные для данных ошибки, а ведь один из наших основных принципов – работать безопасно.
Затем мы исследуем диски вручную и определим, какие из участников массива в настоящий момент исправны, какие – неисправны, и какие из неисправных дисков следует восстанавливать (определяется актуальность данных). Только после этого неисправный диск будет приводиться в пригодное для копирования данных состояние и будет создаваться его посекторная копия.
После всех приготовлений диски анализируются специализированным ПО (в том числе, если требуется, и нашей собственной разработки), определяется конфигурация массива (порядок дисков, размер блока, тип цикла и распределение блоков, смещения (если они есть) и т.п.). Сборка массива осуществлятся в шестнадцатеричном редакторе; после сборки возможно две опции доставки данных – создание полноценного клона массива на другой (исправный) массив (например, на другой NAS) или пофайловое копирование информации на носители заказчика (на другой NAS, на другие диски, и т.п.).
Статистика по обращениям к нам с дисковыми массивами для восстановления данных приводится в этой статье. Как видите, мы восстановили немало массивов, имеем в этом плане огромный опыт и все необходимое для таких работ оборудование: SCSI и SAS-контроллеры, внешние USB-раки для монтажа многодисковых массивов (до 8 SAS-дисков в стойке), специализированное ПО для анализа и сборки массивов. Мы привыкли работать быстро и качественно и всегда готовы оказать вам помощь с воссстановлением данных из RAID, если он вдруг перестал работать.
Задача. Восстановить данные с дискового массива RAID-1+0
Описание проблемы. Массив поступил в виде дисков (не в составе сервера), без какой-либо нумерации или пометок. Диски с интерфейсом SATA, емкость каждого диска 80 ГБ. Все диски исправны. Требуется восстановить почтовые базы данных MS Exchange Server двухлетней давности
Результаты диагностики После сборки массива выяснилось, что база данных не имеет снапшотов и существует в актуальном состоянии, однако для базы включено ведение журналов. Данные за искомый период можно извлечь из имеющихся за все время работы почтового сервера журналов.
Необходимые для восстановления информации процедуры.
1) Создание полной посекторной копии каждого накопителя.
2) Определение конфигурации массива.
3) Сборка массива.
4) Извлечение необходимых для извлечения информации файлов.
4) Извлечение необходимых пользователю данных.
Результат.
Данные восстановлены полностью.
Особенности заказа.
Сборка самого массива не составила никакого труда, проблемы начались с извлечением данных за нужный период. При журналировании почтовой активности ПО MS Exchange Server не сохраняет вложения, указывая лишь их названия, поэтому письма с вложениями удалось восстановить не полностью (без вложений). Однако этот результат удовлетворил заказчика.
Задача. Восстановить данные с дискового массива из сервера с 14 дисками
Описание проблемы. В работу поступил blade-сервер, в составе которого работает 14 SAS-дисков. При запуске сервер не может распознать дисковые сборки (array), соответственно, пользовательские данные не дступны. Однако сигналов о том, что какие-то диски вышли из строя и массив перешел в degraded-состояние, нет.
Результаты диагностики Произведен анализ массива. Выяснено, что по неизвестной причине (скорее всего, саботаж) дисковый массив удлен. Для восстановления данных требуется сборка массива с использованием специализированного ПО, извлечение данных из собранного массива, создание нового массива средствами сервера и копирование восстановленных данных на вновь созданный массив.
Необходимые для восстановления информации процедуры.
1) Определение параметров массива (в нашем случае оказалось RAID5+0)
2) Сборка массива по определенным параметрам.
3) Извлечение пользовательских данных на наши носители.
4) Создание нового массива средствами сервера.
5) Копирование восстановленных данных в созданный массив.
Результат.
Данные восстановлены полностью.
Особенности массива.
Достаточно стандартная схема построения массива, в которой два подмассива RAID-5 объединены посредством страйпирования. Таким образом, при достаточно высокой надежности RAID-5 получается некоторое увеличение производительности и емкости посредством использования технологии страйпирования (RAID-0). Проблема именно этого пользователя заключалась в том, что к утилите конфигурирования массива сервера имелся доступ у большого количства людей, что и привело к саботажу. Мы рекомендовали использовать встроенные средства безопасности серверного ПО, а именно: сменить пароли доступа в админ-панель серверной ОС, на BIOS RAID-части сервера, к службам управления доменами, и уменьшить количество людей, имеющих доступ к этим инструментам.
Задача. Восстановить данные с дискового массива RAID-6
Описание проблемы. В работу поступил дисковый массив RAD-6, состоящий из 6 дисков емкостью 146 GB в исполнении SAS
Результаты диагностики В целях диагностики по стандартной методике проверялся каждый диск. Выяснено, что в массиве из 6 дисков неисправных нет. Проблема с массивом лежит в плоскости вышедего из строя контроллера массива. Принято решение собирать RAID программными средствами.
Необходимые для восстановления информации процедуры.
1) Создание полной посекторной копии каждого накопителя.
2) Определение конфигурации массива.
3) Сборка массива.
4) Извлечение пользовательских данных.
Результат.
Данные восстановлены полностью.
Особенности массива.
В случае с выходом из строя контроллера дискового массива восстановление данных обычно не представляет больих трудностей, так как диски остаются исправными, а в силу выхода из строя управляющего массивом устройства — не производится попыток ребилда.
Дисковые массивы являются не самыми распространенными устройствами хранения данных, поэтому попадают к нам руки не так часто, как другие носители информации.
Дисковый массив – это составное устройство, обычно состоящее из нескольких дисков и объединяющего их контроллера. Разные массивы имеют различное предназначение, это либо увеличение производительности дисковой подсистемы за счет организации одновременной записи данных на разные диски, либо увеличение надежности хранения данных за счет организации «избыточной емкости» (внедрение на отдельный диск или на все диски (более надежный метод) информации для восстановления). При этом, чем выше уровень надежности массива, тем меньше суммарная емкость его дискового пространства и тем меньше скорость его работы.
В зависимости от типа массива и неисправности, восстановление данных может быть как относительно простым, так и довольно сложным. Разберем три примера на одном типе массива для того, чтобы пояснить это.
Пример первый. Простое восстановление данных массива. RAID-0, все диски физически исправны, произведено перестроение (rebuild) массива, после которого с массивом ничего не делалось (данные не записывались, разделы не форматировались, и т.п.). Суть работ: выяснить порядок дисков до процедуры ребилда, выяснить размер страйпа (порция данных в секторах, записываемая последовательно на все диски массива в определенном порядке), построить массив с использованием соответствующего ПО, найти данные и выгрузить на целевой накопитель.
Пример второй. Восстановление данных массива средней тяжести. RAID-0, один из дисков «выпал», но не стучит и не издает посторонних звуков, массив перестал работать. Неисправность выпавшего диска: блокировка микропрограммой в связи с каким-то критически опасным для диска событием (особенно этим знамениты диски Seagate). Суть работ: выяснить проблему неисправного диска, произвести необходимые правки в служебной области, выяснить порядок дисков в массиве, выяснить размер страйпа, построить массив с использованием соответствующего ПО, найти данные и выгрузить на целевой накопитель.
Пример третий. Сложное восстановление массива. RAID-0, один из дисков стучит и скрежещет. Неисправность стучащего диска: блок магнитных головок (БМГ) вышел из строя в момент парковки, одна из головок не зашла на парковочную рампу и загнулась. Головка при старте не может спозиционироваться, микропрограмма выдает ошибку и заставляет накопитель повторно искать сервометки. Как результат – стук. Суть работ: подобрать запчасти для неисправного диска, произвести замену БМГ, выяснить порядок дисков в массиве, выяснить размер страйпа, построить массив с использованием соответствующего ПО, найти данные и выгрузить на целевой накопитель.
Работа, естественно, идет только с клонами дисков-пациентов, оригиналы мы не трогаем никогда. В нашем деле это настолько естественно, что не обсуждается: работая с клоном, мы всегда имеем возможность экспериментировать, а в случае неудачи – вернуться к исходному состоянию, заново склонировав источник.
Понятно, что восстановление данных с массивов разных типов и с разными типами неисправностей происходит по-разному. Но здесь мы бы хотели поговорить о другом – о надежности массивов и о том, какие неисправности массивов мы встречаем чаще, а какие – реже.
В источниках в Сети можно найти немало информации о том, насколько надежны те или иные типы массивов. В частности, все мы знаем, что массивы с контролем четности (RAID-5, RAID-6 и их разновидности) имеют более высокий уровень надежности по сравнению с массивами, направленными на максимальное повышение производительности (RAID-0). Но насколько все это справедливо на практике?
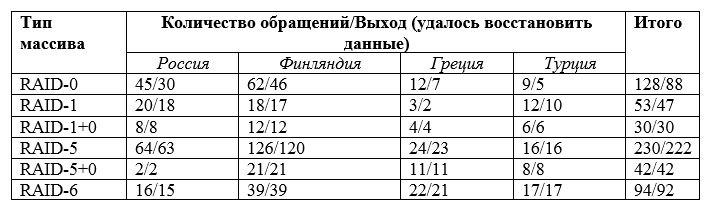
Представляем вам уникальные данные, которые собирались в течение 10 лет в 4 странах: России, Финляндии, Греции и Турции. В нашем обзоре представлены наиболее распространенные типы RAID; конечно, нам приходилось работать и с менее распространенными массивами типа RAID-3, RAID-4, Hybrid RAID от Synology, DROBO, но они попадали к нам настолько редко, что ни о какой статистике говорить нельзя.
Представляемые нами данные приведены в таблице 1. Из этой таблицы сразу же очевиден тот факт, что наиболее часто используются массивы с контролем четности RAID-5, и ненамного реже – быстрые массивы без контроля четности RAID-0. Преимущественное использование RAID-5 объясняется двумя факторами: при относительно небольшой потере производительности и емкости (емкость массива RAID-5 равняется емкости всех составляющих его дисков минус один диск) этот массив поразительно живуч и продолжает работать даже в том случае, когда один из дисков массива вышел из строя. Активное использование массивов RAID-0 объясняется их высокой производительностью: контроллер реализует одновременную запись данных на все диски массива.
И те, и другие типы массивов наиболее часто попадались нам в NAS-боксах (NAS: Network Attached Storage, сетевой накопитель), при этом использование массивов типа RAID-0 в NAS выглядит не совсем логичным, ведь в любом случае скорость массива ограничивается скоростью локальной сети, а она весьма далека от предельно возможных скоростей системной шины компьютера.
Массивы типа RAID-1 («зеркало») и RAID-6 (двойной контроль четности) также, как и предыдущая «пара» массивов, встречаются примерно с одинаковой частотой, приблизительно раза в три реже, чем массивы RAID-5 и RAID-0.
Наконец, массивы смешанного типа (RAID-1+0 и RAID-5+0) являются самыми редкими в нашей работе.
Таблица 1
Распределение восстановлений данных с дисковых массивов, попадавших к нам в работу за период с 2007 по 2017 гг., по типам массивов и по странам
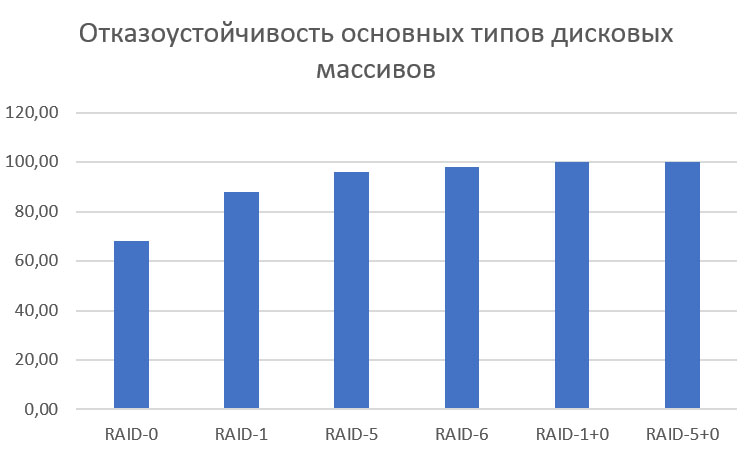
Наиболее интересными являются данные по отказоустойчивости дисковых массивов. Массивы смешанного типа (RAID-1+0 и RAID-5+0) ожидаемо являются лидерами надежности: это достаточно просто объясняется тем, что массивы являются самодублирущимися, и для их «полного» уничтожения требуется, чтобы из строя без возможности восстановления было выведено не менее половины составляющих их дисков. Правда, очевиден и недостаток таких массивов: при очень высоком уровне надежности в первом случае теряется как минимум половина емкости дисков, включаемых в массив, а во втором – даже больше (половина минус 1 диск на каждый кластер составного массива). Именно поэтому данные типы массивов не слишком популярны.
Надежность массивов RAID-1, RAID-5 и RAID-6 растет линейно: это 88.6, 96.5 и 97.9% соответственно. И это также достаточно легко объяснимо: в массивах RAID-1 («зеркало») производится одновременная запись данных на два и более накопителей; соответственно, выход из строя одновременно их всех маловероятен, а все ошибки, связанные с такими массивами, приводящие их в наши лаборатории, связаны со сбоями контроллера или с ошибками пользователя (удаление данных, форматирование и т.п.). В массивах RAID-5 имеется «избыточная» емкость, кратная объему одного диска; выход из строя любого диска массива не фатален для данных. Ну а в массивах RAID-6 «избыточная» емкость распределяется уже по двум накопителям, соответственно, массив может без вреда для данных потерять любые два диска, что делает систему еще более надежной.
Массивы типа RAID-0 оказались ожидаемо наименее надежными – из всех массивов этого типа, попавших к нам в работу, удалось восстановить данные лишь в 68.7% случаев. Основная причина столь низкого процента выхода – необратимые повреждения одного или нескольких (реже – всех) дисков массива, которые оказалось невозможно устранить. Наиболее частым оказалось запиливание одного или нескольких дисков массива. Распределение отказоустойчивости массивов приведено на диаграмме ниже.
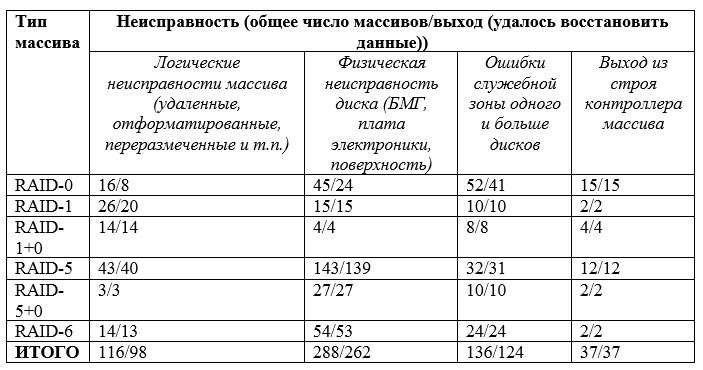
Таблица 2
Распределение неисправностей дисковых массивов, попадавших к нам в работу за период с 2007 по 2017 гг.
Статистика распределения неисправностей дисковых массивов, прошедших через нас за 10 лет, приведена в таблице 2. Все неисправности мы сгруппировали в четыре класса: логические, физические, неисправности служебной зоны и неисправности контроллера массива. Распределение получается довольно любопытным.
Составные массивы (RAID1+0, RAID5+0) наиболее устойчивы ко всем типам неисправностей.
Массивы RAID-0 оказались наименее устойчивы к логическим проблемам (удаленные данные, форматирование, перераспределение разделов и т.п.) – фактически удалось восстановить информацию в объеме, необходимом заказчику, лишь для половины таких заказов. Также весьма плачевно выглядит ситуация с физическими неисправностями дисков в массивах этого типа: восстановлению подлежало около половины поступивших с этой неисправностью устройств. Объясняется такое распределение следующим: физически неисправные диски массива не всегда возможно привести в состояние, при котором возможно их вычитывание; при этом потеря даже одного диска фатальна для данных. Другая причина – диск удавалось реанимировать лишь частично (например, при выходе из строя одной из поверхностей удавалось считать остальные), но «дыры» в страйпах были так велики, что необходимые заказчику данные или вообще не восстанавливались, или восстанавливались с повреждениями, которые заказчик не мог принять. Картину усугубляет тот факт, что дисковый массив – это не то устройство, которое обычно находится на виду, и если данные с него не используются постоянно, то от момента физического выхода из строя накопителя, входящего в массив, до обнаружения этого факта, может пройти довольно много времени; устройство при этом не обесточено, диски крутятся, а неисправность прогрессирует (особенно если это запил или царапина).
Распределение неисправностей массивов типа «зеркало»: удавалось восстановить практически все массивы с неисправностями дисков или контроллера, не удавалось восстановить некоторое количество логических заказов.
Плохие результаты по восстановлениям данных с массивов RAID-0 и RAID-1 с логическими проблемами объясняется перезаписью данных, от которой ни тот, ни другой тип массива не защищен. Как правило, пользователи не сразу замечают, что данные были удалены, и продолжают некоторое время использовать массив, перезаписывая на нем информацию. Если же массив форматируется или переразмечается, то обычно это сопровождается массивной перезаписью данных (установка операционной системы или «возвращение» назад зарезервированных данных – чаще всего зарезервированных в далеком от полного объеме). В этом ключе массивы RAID-5 и RAID-6 с одним или (реже) двумя давно исключенными из массива дисками позволяли восстановить более «старую» логику, что давало больший выход годных для заказчика данных и как результат – большее количество успешно выполненных восстановлений. Именно поэтому мы всегда просим предоставить в работу все диски, которые когда-либо устанавливались в салазки RAID-сервера.
Массивы с контролем четности (RAID-5, RAID-6) поступали в работу главным образом с физическими неисправностями дисков. Этому есть два объяснения: наиболее распространенное – при выходе из строя одного из дисков массива массив продолжал работать, и заказчик просто не замечал, что устройство работает в downgraded-состоянии; соответственно, когда из строя выходил уже следующий диск (или диски), массив отказывал, и только после этого поступал в работу. Наименее распространенное объяснение – диски в массивах с контролем четности испытывают увеличенные нагрузки (запись-чтение происходят постоянно, так как контроллер все время выполняет вычислительные операции и записывает их результаты на диски), они быстрее изнашиваются и, соответственно, выходят из строя по причине износа. Наиболее характерен такой износ в тех случаях, когда для дискового массива используются не предназначенные для этого диски, например – в серверную стойку в массив RAID-5 устанавливаются обычные накопители для ноутбука.
Физические ошибки контроллера встречаются редко для всех типов массивов, и являются самой «хорошей» неисправностью, так как при ошибках контроллера удается восстановить все 100% данных. Это связано с тем, что, когда контроллер выходит из строя, на диски не производится запись; кроме того, при неисправном контроллере нельзя произвести rebuild массива, а это означает, что массив застрахован от ошибок пользователя.
Какие можно сделать выводы из приведенных нами данных?
Прежде всего, если вам позарез нужен быстрый массив, озаботьтесь системой резервного копирования, так как при выходе такого массива из строя достаточно велики шансы (более 25%), что данные из него в случае отказа не получится восстановить.
Если вам нужен массив максимальной надежности, то используйте составной массив. В нашей практике не было ни одного случая, когда из такого массива не удалось восстановить данные. Конечно, вы серьезно потеряете в емкости, но зато получите практически 100%-надежность. С учетом цен на современные накопители, потери в емкости в денежном эквиваленте оказываются минимальными.
Ну, а если вы хотите достичь баланса и получить и надежный, и быстрый массив, и при этом не сильно проиграть в емкости, то лучше всего использовать массив RAID-5. Он весьма незначительно отличается по надежности и от RAID-1, и от RAID-6, которые оба проигрывают ему в емкости, а RAID-6 – еще и в производительности.