В настоящее время, когда объемы информации растут в геометрической прогрессии, практически перед каждым пользователем встает вопрос приобретения более емких носителей информации для обеспечения сохранности данных. Другими словами, приобретаются емкие накопители – хранилища данных, на которые время от времени сливаются семейные фотографии, фильмы, музыка и тому подобный контент. Как правило, такие НЖМД не работают постоянно (обычно включаются не чаще одного раза в неделю). Многие предпочитают использовать внешние USB-устройства.
Однако, даже при нечастых включениях, накопители все же выходят из строя, и довольно часто. Это происходит из-за особенностей изготовления НЖМД бюджетных линеек, которые в подавляющем большинстве и продаются в компьютерных магазинах. Нами разработана и успешно применяется методика продления жизни НЖМД, позволяющая в 1.5 — 2 раза увеличить их срок службы. Данная методика разработана и опробована на накопителях трех производителей: Toshiba, Seagate и Western Digital. Методика обкатывалась почти 3 года, и теперь мы готовы предложить эту услугу потребителю:
Послепродажная подготовка НЖМД Toshiba, Seagate, Western Digital к работе.
Стоимость: 500 сом. Время накопителя в работе: 2 дня. Гарантия на работу: 2 года. Негарантийными случаями являются: ударенные, уроненные накопители, накопители с горелой электроникой или другими следами электрического шока, накопители, пострадавшие в огне или воде.
<Услуга включает в себя: подготовку (в том числе и химическую обработку) платы электроники накопителя, анализ и необходимую модернизацию микропрограммы накопителя и его полное выходное тестирование. По результатам тестирования мы предоставляем краткий отчет о состоянии накопителя и либо рекомендуем его к использованию и даем нашу гарантию, либо рекомендуем заменить накопитель. Рекомендации к замене появляются в трех случаях: сильное «проседание» атрибутов SMART во время тестов (мы используем уникальную систему стресс-тестирования, которая позволяет «пройтись» по всем слабым местам современного жесткого диска); обнаружение на диске дефектных или нестабильных секторов (проблемы с поверхностью); сильный перегрев определенных микросхем во время выполнения тестов (нарушение температурного режима).
Внимание! Услуга оказывается только для новых накопителей. Накопители, которые уже были в эксплуатации более трех месяцев, под эту услугу не попадают.
RAID – технология старая, проверенная временем и надежная. RAID – аббревиатура, означающая Rebundant Array of Independent Drives (Избыточный массив независимых дисков). Что это значит? Если объяснять просто, то это такое устройство, которое объединяет в один диск несколько дисков, и объединяет по-разному. Но результат всегда одинаковый: для пользователя это будет единый накопитель, на который он может скопировать свои файлы.
Хорошо, спросите вы, а зачем тогда нужен этот самый RAID, если можно с таким же успехом просто подключить жесткий диск? Естественно, раз он был придуман, то не просто так. Какие задачи решает дисковый массив?
Дисковый массив из 8 дисков Western Digital Red емкостью 3 ТБ каждый. RAIR-0, общая емкость массива 24 ТБ
Основные функции дисковых массивов
Первая – это повышение производительности. Организация нескольких дисков в единое устройство хранения информации позволяет записывать данные пользователя одновременно на все диски массива порциями, тем самым увеличивая (в теории) скорость работы дисковой подсистемы кратно количеству дисков в ней. На практике, конечно, прирост производительности не кратен числу дисков, но все равно, он весьма высок и превышает обычные для стандартных жестких дисков скорости как минимум на 50%.
Вторая – это повышение емкости. Несколько дисков, объединенных в массив, будут иметь или суммарную емкость всех дисков массива, или немногим менее (обычно суммарная емкость всех дисков минус емкость одного или двух дисков).
Третья – это повышение надежности. Неспроста в расшифровке аббревиатуры RAID присутствует слово «избыточность» — большинство типов дисковых массивов реализуют те или иные механизмы защиты данных от потерь. Единственный тип RAID, в котором не реализована избыточность – это RAID-0, или, как его еще называют, «страйп». Этот тип массива использует все диски для хранения пользовательских данных, он самый быстрый из всех типов дисковых массивов и позволяет получить самую большую конечную емкость устройства, но при этом он абсолютно не защищен от сбоев, и в случае любой неисправности любого члена массива RAID-0 данные на нем теряются.
Как это работает? В целом просто, как и все гениальное.
Диски разделяются на блоки, а блоки чередуются в определенном порядке. Когда нужно записать информацию, контроллер распределяет ее по свободным блокам. Вот и все. Казалось бы, что может быть надежнее?
Типы дисковых массивов
Сохранение общего принципа «блочная запись данных в определенном порядке» порождает массу его разновидностей. Можно записывать данные блоками с чередованием на каждом диске, через диск, через несколько дисков; можно записывать информацию блоками разной величины; можно разделить блоки на блоки с данными и блоки с информацией для восстановления (избыточность), и также чередовать их по-разному. В общем, вариантов масса. Это и порождает основные проблемы восстановления данных с дисковых массивов.
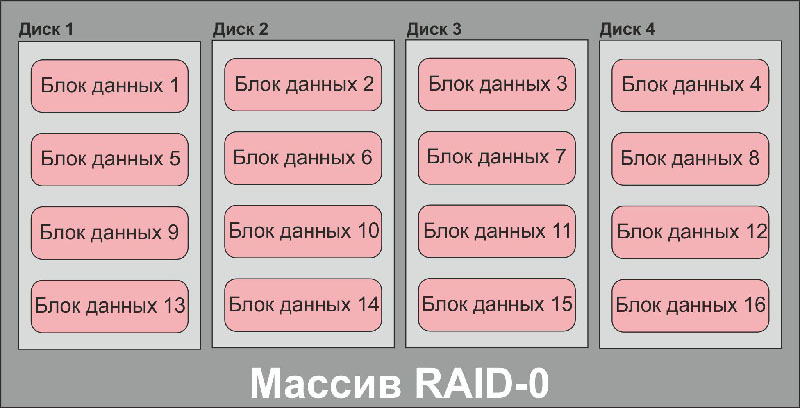
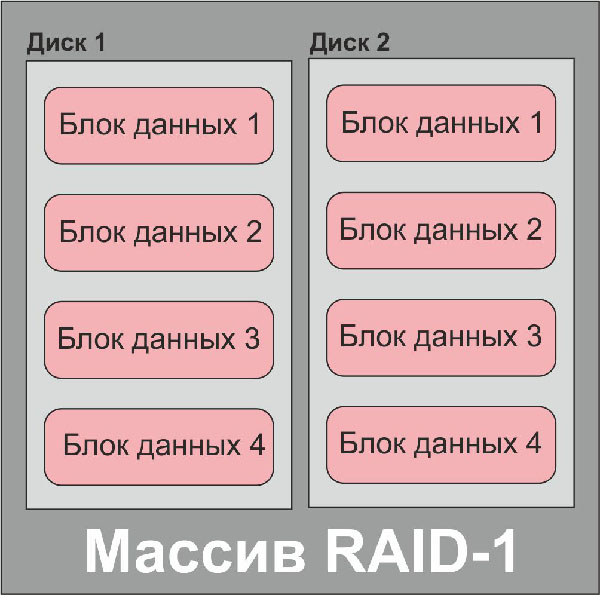
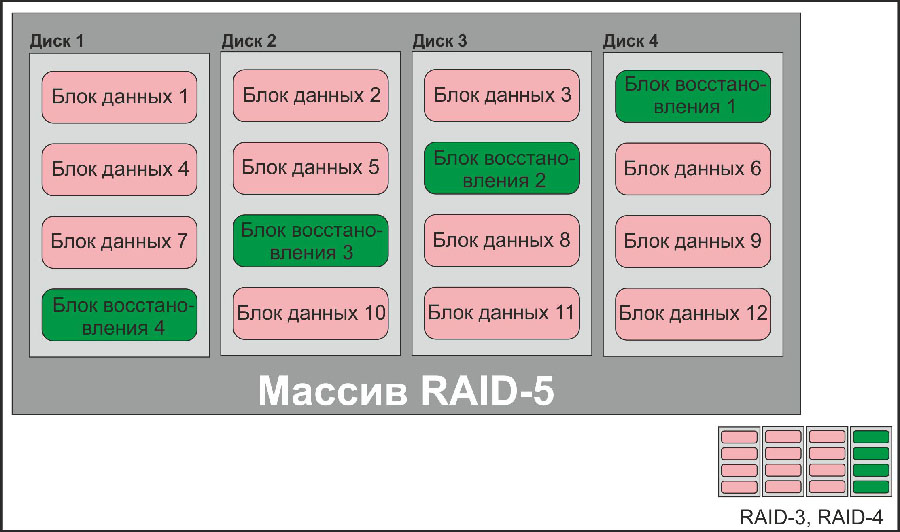
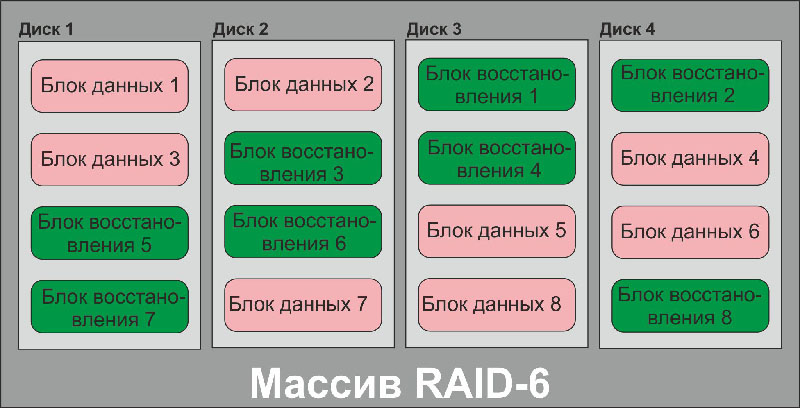
Всем известно, что RAID-массивы бывают разными: RAID-0 (страйп), RAID-1 (зеркало), RAID-3, RAID-4 (массивы с контролем четности, вынесенным на отдельный диск), RAID-5, RAID-6 (массивы с контролем четности блочного типа). Мы не будем описывать эти типы дисковых массивов – в интернете об этом информации более чем достаточно; на рисунках ниже изображено, как они работают.
Блок-схема дискового массива типа RAID-0
Блок-схема дискового массива типа RAID-1
Блок-схема дискового массива типа RAID-5, с объяснением типов массивов RAID-3 и RAID-4
Блок-схема дискового массива типа RAID-6
Реализация избыточности: XOR и коды Рида-Соломона
Намного интереснее то, как реализуется избыточность. Для этого используется два логических механизма: XOR (RAID-3, RAID-4, RAID-5) и XOR + код Рида-Соломона (RAID-6).
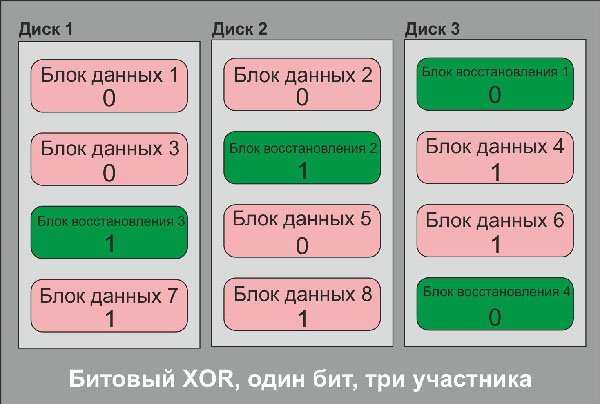
Что такое XOR? Это логический оператор, который принято обозначать как «исключающее или». Работает он просто и начинает иметь смысл при трех участниках оператора: первом слагаемом, втором слагаемом и результате. Смысл оператора заключается в том, что зная два из трех его участников мы всегда можем точно назвать третий. Конечно, XOR можно организовать и для четырех, и для пяти, и для большего количества участников – просто сами операции восстановления недостающего члена ряда будут сложнее. Как это работает? Давайте рассмотрим на примере ряда из трех членов (пусть для простоты это будет три диска с однобитовым размером блока, чтобы нам было проще представить механизм):
XOR-матрица для трех участников по одному биту каждый
Схема восстановления утерянного участника при помощи XOR-матрицы
Мы видим, что при утере любого из дисков содержимое утерянного байта в каждом блоке утерянного диска может быть восстановлено из двух других с использованием операции «исключающее или». Очевидно, что при потере одного диска, основанного на этом принципе восстановления (избыточности), массив продолжит работать нормально, хотя и медленнее обычного, так как много времени будет тратиться контроллером массива на расчет недостающих битов информации. По этой причине дисковые массивы с избыточностью обычно делаются с небольшим размером блока (до 256 секторов), так как пересчет больших блоков слишком сильно нагружает контроллер и общая производительность массива при больших блоках падает просто катастрофически; кроме того, активное использование контроллера в режиме постоянного пересчета данных неизбежно приведет к его повышенному износу и по этой причине – преждевременному выходу из строя.
Более высокий уровень надежности дискового массива можно обеспечить, только реализовав дополнительный механизм восстановления утерянных данных. Такой механизм был реализован в массивах RAID-6, он позволяет массиву пережить потерю сразу двух дисков, и минимальное количество членов массива, соответственно, будет четыре. Основан этот механизм на использовании двух независимых систем пересчета данных: XOR (о нем мы сказали выше) и коды Рида-Соломона. В массивах типа RAID-6 чередуются блоки данных, блоки XOR и блоки кодов Рида-Соломона так, что при выходе из строя одного или даже двух дисков содержимое этих дисков может быть пересчитано контроллером, и массив продолжит работать (данные будут доступны). Что же такое коды Рида-Соломона?
Если говорить максимально просто, то код Рида-Соломона – это битовая матрица, позволяющая при утере одного или двух ее участников рассчитать их содержимое по остальным. Казалось бы, чем отличается код Рида-Соломона от XOR? Отличие в том, что коды Рида-Соломона позволяют восстановить битовое значение при отсутствии не одного, а двух компонентов. Для этого используются более сложные алгоритмы: поля Галуа, синдром ошибки и прямое преобразование Фурье. Если при использовании XOR восстановление возможно только при сохранении цикличности расположения битов информации, то при использовании кодов Рида-Соломона сохранение цикличности уже не требуется, так как математика контроллера сама способна рассчитать положение ошибок и скорректировать их.
Естественно, использование такого сложного алгоритма восстановления данных приведет, в случае утери одного или двух дисков из массива RAID-6, к сильному износу контроллера и, как следствие, к его преждевременному выходу из строя.
Состояние массива с избыточностью: нормальное, деградировавшее, неисправное
Любой дисковый массив, имеющий избыточность, по своему состоянию разделяется на нормально работающий (все диски массива исправны и массив функционирует нормально, данные защищены), деградировавший (degraded) (один или два (в зависимости от типа RAID) диска массива неисправны, массив функционирует с пересчетом отсутствующих дисков, данные не защищены) и неисправный (вышло из строя больше дисков, чем поддерживает избыточность, контроллер не имеет возможности рассчитать данные на вышедших из строя дисках, массив перестал существовать как устройство хранения информации).
Нормально работающий массив – его естественное состояние. Для того, чтобы не потерять массив в случае выхода из строя одного из его членов, было внедрено понятие «горячая замена» (hot spare) – пустой диск, единственная функция которого – принять на себя пересчитанные контроллером данные вышедшего из строя накопителя. Такой диск после переноса на него рассчитанных данных включается в массив, а вышедший из строя диск из него исключается. Эта процедура называется «перестроить массив» (RAID rebuild). Как правило, во время перестройки (ребилда) массив работает значительно медленнее, чем в нормальном состоянии. По этой причине в случае ребилда деградировавшего массива пользователь может его перезагрузить («что-то зависает, надо перезапустить»). Результатом такой перезагрузки может стать переход массива из состояния «деградировавший» в состояние «неисправный». Во избежание подобных последствий, при наличии настроенного диска горячей замены, в случае значительной потери производительности массива зайдите в утилиту его настройки и мониторинга и посмотрите, чем именно сейчас занят массив. Если он покажет вам процесс rebuild – не трогайте массив до его окончания.
Состояние массива без избыточности: исправен и неисправен
Для массивов без избыточности (RAID-0 и RAID-1) возможно только два состояния: массив исправен (все диски массива работают и данные доступны) и массив неисправен (один или несколько дисков массива вышли из строя, данные недоступны).
Если с массивами RAID-0 выход одного или нескольких участников массива из строя приводит к образованию «дыр» в данных (те места, где должны быть блоки данных из вышедших из строя носителей), то с массивами RAID-1 (зеркало) все намного интереснее. По простой логике зеркало, или массив с полным дублированием диска, не должно приводить к потере данных в случае выхода из строя одного из участников. На практике это так далеко не всегда. Довольно часто (особенно в случае использования в массиве дисков одного производителя и одной модели) один диск «клонирует» не только данные со второго, но и его ошибки, что может привести к одновременному выходу из строя обоих дисков с идентичными симптомами. В настоящее время зеркалирование – уже отмирающая технология, предпочтение отдается блочным массивам с избыточностью как более надежным.
Составные массивы. Кластеры. Локусы. Современные системы хранения данных
Конечно же, свет вовсе не сошелся клином на тех типах RAID, которые мы перечислили выше; производители всевозможных устройств с удовольствием применяют различные алгоритмы, комбинации и решения для реализации наиболее (по их мнению) быстрых и надежным типов массивов. Один из методов «улучшения» RAID – применение технологий составных массивов.
В самом простом случае составной дисковый массив – это два или больше массива, объединенных в один. Например, два RAID-5, которые объединены в зеркало (RAID-1). Или два страйпа (RAID-0), объединенных в зеркало. И т.п. По типу объединения такие массивы обычно имеют двойную цифровую кодировку (RAID50 или RAID5+0, RAID10 или RAID1+0, и т.д.). Составление массива из нескольких добавляет массиву надежности.
Более сложные структуры создаются уже для промышленных систем хранения данных, они призваны обеспечить большие емкости при высоком уровне отказоустойчивости. Как правило, это составные массивы иерархического типа, реализованные по принципу матрешки: более мелкие массивы помещаются в более крупные, и так до тех пор, пока на верхушке не остается один, наиболее крупный, RAID. Например, такая структура:
Десять массивов RAID-5, объединены попарно в массивы RAID-0 (таких массивов получается пять), эти массивы RAID-0 объединены в RAID-6; четыре таких массива RAID-6 объединены в RAID-0. Как разграничить такую схему?
Для этого придумана специальная терминология.
Промышленное устройство хранения информации (или просто дисковый массив) – это окончательный продукт взаимодействия всех дисков в системе, то свободное место, которое он предоставляет для использования.
Кластер – первичная ячейка хранения данных, объединение нескольких массивов первого или второго уровня (в нашем примере кластером является попарное объединение массивов RAID-5 в массив RAID-0).
Локус – объединение кластеров.
Таким образом, простым определением промышленного устройства хранения информации будет: промышленное устройство хранения информации – это иерархическое объединение в единое дисковое поле локусов кластеризованных дисковых субъединиц.
Физическая реализация дисковых массивов
Как дисковые массивы реализуются на практике? Возможно два метода: программный и аппаратный.
Массив на программном уровне может быть создан даже на базе одного диска (в RAID программно собираются участки его поверхности). Обычно программный массив собирается в Linux, реже – Mac или Windows. Инструменты создания программных массивов в Linux/Unix системах намного мощнее, удобнее и гибче, чем в Windows, поэтому в подавляющем большинстве NAS (Network Attached Storage) для сборки массива используется Linux. Соответственно, собирая программный массив блочного типа с избыточностью, нужно быть готовым к тому, что он будет «отъедать» часть ресурсов процессора и оперативной памяти для обсчета избыточности.
Массив на аппаратном уровне собирается с использованием специализированного RAID-контроллера – это или внешняя карта расширения, устанавливаемая в PCI или PCI-E слот, или интегрированный в материнскую плату микрочип. В любом случае, всю математику, а также хранение настроек, логов ошибок и т.п., берет на себя уже не программная часть, реализванная в операционной системе, и не ресурсы компьютера, а аппаратная часть контроллера.
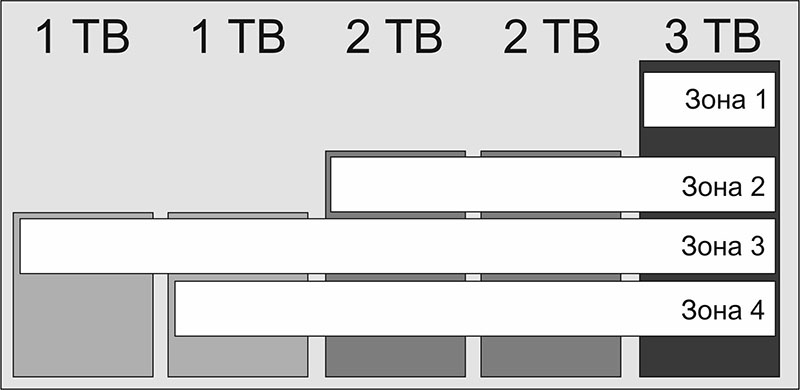
В большинстве случаев для организации дискового массива требуются диски одинакового объема. Однако некоторые контроллеры позволяют реализовывать блочные дисковые массивы с избыточностью и на дисках разного объема: DROBO, Synology и т.п. Такие массивы строятся на принципе разделения общего дискового пространства на зоны, из которых собирается конечный массив. Эти массивы имеют свои собственные маркетинговые названия (например, Beyond RAID у DROBO, Hybrid RAID у Synology, и т.п.), однако суть всегда остается одинаковой: это, во-первых, блочный массив, а во-вторых, у него имеется реализованная циклическим способом избыточность.
На каких дисках строятся дисковые массивы
В принципе для построения массива нет ограничений по используемым носителям. Это могут быть и традиционные жесткие диски с любым интерфейсом (SCSI, SAS, SATA, PATA), и твердотельные диски с любым интерфейсом (SATA, NVMe, M.2 и т.п.), и карты памяти (в китае даже выпускаются особые платы расширения, позволяющие сделать из нескольких карт SD один твердотельный накопитель – при этом карты памяти работают как RAID-0).
Массивы на SSD собираются в дата-центрах, для которых приоритетным является не объем хранилища, а его производительность – например, там, где требуется обрабатывать медиа-контент (видео в разрешении 4К и 8К, фотографии, снятые камерами с разрешением больше 32 мегапикселей, и т.п.). Это киностудии, медиахранилища (например, облако iCloud) и т.п.
На жестких дисках собираются массивы тогда, когда объем важнее производительности – и, естественно, когда построить массив на SSD не позволяет бюджет (твердотельные диски намного дороже жестких). Массивы на SATA или PATA-дисках (последние уже почти не встречаются) собираются в бюджетном сегменте, они дешевле всех других и позволяют строить хранилища довольно внушительного объема.
SCSI или SAS диски используются в бизнес- или enterprise-решениях, их отличает более высокая степень надежности, чем SATA/PATA диски. Кроме того, обычно SCSI/SAS диски разрабатываются именно для использования в серверах, поэтому их отличает (обычно) более высокая скорость вращения шпинделя, уменьшенное время поиска информации, высокие скорости передачи данных.
Массивы на картах памяти строят в подавляющем большинстве случаев обычные пользователи, хотя такие массивы могут быть реализованы в некоторых профессиональных камерах для повышения безопасности данных (две карты памяти, которые работают в режиме RAID-1). Массив на картах памяти наименее надежен, так как качество карт памяти значительно уступает качеству жестких или твердотельных дисков, карты памяти имеют гораздо больше шансов на выход из строя и, наконец, они просто значительно медленнее дисковых накопителей.
Восстановление дисковых массивов в компании IT-Doctor
Наш опыт в области восстановления данных составляет более 25 лет, и немалую часть этого времени мы посвятили дисковым массивам. Основная часть наших клиентов обращалась с устройствами NAS и с внешними USB-дисками, оборудованными внутри 2 – 4 накопителями. Как правило, в таких устройствах реализуется либо массив RAID-0, либо RAID-5. Подобного рода массивы восстанавливаются обычно очень быстро, так как нами накоплена большая база стандартных конфигураций дисковых массивов для такого рода устройств. В 90% случаев при исправных дисках при обращении к нам с устройством NAS или внешним диском, построенным по архитектуре RAID, мы восстановим данные в тот же или на следующий день.
В более сложных случаях, когда применяется нетривиальная конфигурация массива, или когда один или несколько дисков в массиве вышли из строя в разное время, и требуется определить, какой из них несет актуальные данные, а какой следует игнорировать, процесс восстановления данных может занять 2 – 3 дня. С чем это связано?
Прежде всего, мы обязательно сделаем посекторную копию каждого диска массива. Это делается даже в том случае, если все диски в массиве исправны. Работа с копией полностью исключает фатальные для данных ошибки, а ведь один из наших основных принципов – работать безопасно.
Затем мы исследуем диски вручную и определим, какие из участников массива в настоящий момент исправны, какие – неисправны, и какие из неисправных дисков следует восстанавливать (определяется актуальность данных). Только после этого неисправный диск будет приводиться в пригодное для копирования данных состояние и будет создаваться его посекторная копия.
После всех приготовлений диски анализируются специализированным ПО (в том числе, если требуется, и нашей собственной разработки), определяется конфигурация массива (порядок дисков, размер блока, тип цикла и распределение блоков, смещения (если они есть) и т.п.). Сборка массива осуществлятся в шестнадцатеричном редакторе; после сборки возможно две опции доставки данных – создание полноценного клона массива на другой (исправный) массив (например, на другой NAS) или пофайловое копирование информации на носители заказчика (на другой NAS, на другие диски, и т.п.).
Статистика по обращениям к нам с дисковыми массивами для восстановления данных приводится в этой статье. Как видите, мы восстановили немало массивов, имеем в этом плане огромный опыт и все необходимое для таких работ оборудование: SCSI и SAS-контроллеры, внешние USB-раки для монтажа многодисковых массивов (до 8 SAS-дисков в стойке), специализированное ПО для анализа и сборки массивов. Мы привыкли работать быстро и качественно и всегда готовы оказать вам помощь с воссстановлением данных из RAID, если он вдруг перестал работать.
Пару дней назад обратился клиент с нетривиальным случаем: USB-флешка Kingston Data Traveler Locker+. Накопители этого типа имеют аппаратное шифрование, соответственно, после выхода устройства из строя специалисту по восстановлению данных приходится бороться не только с непосредственно неисправностью, но также и со всеми проблемами, порождаемыми шифрованием.
В нашем случае устройство было исправным, пароль на устройство имелся, но оно было отформатировано. Как оказалось, даже этого хватает, чтобы потерять доступ к данным. Файловая система FAT32, в которой форматируется подавляющее большинство флеш-устройств, не сохраняет никаких следов файловых записей при формате, сама таблица полностью перезаписывается, и после такого форматирования восстановление файловой структуры обычно достигается нетривиальными методами (анализ всех данных с построением файловых деревьев по сохранившимся записям о файлах и папках). Однако в случае с шифрованием анализировать нечего, и если таблицы FAT обнулены, то взять данные о файлах и папках уже просто неоткуда.
Но хуже всего не это. В обычных условиях даже при полной потере данных о расположении файлов (file allocation table – FAT) как минимум часть данных можно восстановить так называемым черновым восстановлением – поиском файлов по их сигнатурам. При этом для поиска фрагментированных файлов используются особые программные продукты собственной разработки (следите за разделом о наших разработках на нашем сайте, мы обязательно познакомим вас с этим ПО). В целом с использованием чернового восстановления получается восстановить от 50 до 99.99% всех потерянных данных. Единственное неудобство чернового восстановления заключается в том, что на выходе мы получаем просто набор файлов одного типа: Word документы, JPEG-картинки, и т.п., разложенные по соответствующим папкам. Однако, во-первых, это лучше, чем ничего, а во-вторых, объемы записываемой на флеш-карты информации обычно невелики, и их ручная обработка после восстановления не занимает много времени.
Вернемся к нашему Kingston Data Traveler Locker+. Устройство нормально определяется в системе, полностью отдает «поляну», однако поляна, увы, зашифрована. Файловой системы нет (флешка отформатирована). Пароль на флешку имеется и работает, то есть получить доступ к данным мы можем. Флешка не шифрует файловые таблицы, шифруется только область данных (что само по себе довольно необычно, но вполне оправдано: зачем шифровать область, описывающую расположение файлов, если без ввода пароля флешка все равно не откроется?). Однако механизм шифрования таков, что шифруются не отдельные сектора, а вся «поляна» флешки целиком, и если файловых таблиц нет, то узнать, где лежали те или иные файлы, невозможно.
Так было и в этом случае. Восстановление данных с самой флеш-карты оказалось невозможным (сильный алгоритм шифрования, зашитый в микроконтроллере уникальный ключ без возможности его «подсмотреть»), однако нашему заказчику мы все же помочь смогли. Все дело в том, что эти флешки автоматически используют резервирование данных в облако по технологии USBtoCLOUD, и если знать эту их особенность, то потерять данные оказывается довольно сложно.
Зашифрованная карта Kingston DataTraveler Locker+, область FAT
Зашифрованная карта Kingston DataTraveler Locker+, область данных
Наверное, почти каждому владельцу компьютера знакомы эти словосочетания – «бэд-блоки» или «дефектные сектора». Все их боятся и, когда их находят, обычно начинается паника. В этой статье я расскажу про дефектные сектора, что это такое, нужно ли их бояться и как с ними бороться.
Дефекты – что это?
Поверхность жесткого диска имеет строгую организацию. Основная единица поверхности – сектор; это порция данных, имеющая определенную структуру. Как правило, эта структура включает в себя заголовок, тело (которое, собственно, и несет данные) и контрольную сумму. У некоторых накопителей сектор может также нести служебную информацию (маркер физического адреса, маркер принадлежности к поверхности и т.п.), но для нас это не важно – важны именно заголовок, тело и контрольная сумма. Сектора организованы в треки, или цилиндры, а последние, в свою очередь – в зоны.
Поверхность жесткого диска, хотя и изготавливается в идеальных условиях, ввиду громадного количества единиц хранения данных (секторов) не может быть изготовлена без дефектов. Эти дефекты поверхности могут быть различной природы – от банальных царапин до мест, где нанесение ферромагнитного состава было проведено с ошибками (тоньше или толще чем нужно). Попадающие в эти области сектора, очевидно, не будут нормально работать, и на этом основании исключаются из использования и помечаются как дефектные.
Таким образом, дефектные сектора – это любые проблемы поверхности жесткого диска, SSD или флеш-карты, приводящие к затруднению или невозможности операций чтения и записи.
Какие бывают дефекты?
Дефектные сектора принято разделять по происхождению и по времени возникновения. По происхождению дефекты бывают:
Аппаратные – дефектный сектор образовался в результате физического повреждения поверхности;
Программные – дефектный сектор образовался в результате сбоя программного обеспечения, причем не важно – пользовательская это программа или микропрограмма накопителя.
По времени возникновения дефекты делятся на: заводские и послезаводские.
Заводские дефекты – те, которые были обнаружены и скрыты на заводе-изготовителе.
Послезаводские дефекты – те, которые образовались уже после выпуска устройства с завода и были скрыты в процессе его эксплуатации.
Что такое дефект-менеджмент?
Скрытие дефектных секторов и оперирование скрытыми секторами называется дефект-менеджментом (управление дефектами). Суть его заключается в обеспечении бесперебойной работы диска с использованием только исправных, нормально читающихся и записывающихся областей поверхности. Упрощенно дефект-менеджмент построен по следующей схеме:
1) обработка заводского списка дефектов и построение системы трансляции накопителя с его использованием;
2) обработка растущего списка дефектов и подстройка имеющейся системы трансляции с его использованием;
3) постоянный мониторинг состояния поверхности;
4) добавление в случае необходимости дефектов в растущий список дефектов и перестроение системы трансляции в связи с этим.
Что такое система трансляции (транслятор)? На диске все сектора, и хорошие, и плохие, расположены один за другим; для того, чтобы использовать только хорошие сектора, требуется пропустить плохие. Этим и занимается транслятор: в самом упрощенном представлении это карта поверхности, на которой неисправные области (бэд-блоки) имеют соответствующее обозначение и при работе диска будут пропускаться, а исправные имеют сквозную нумерацию (с пропуском неисправных) и будут использоваться.
Система трансляции в современных дисках учитывает не только сектора, но и другие единицы организации дискового пространства: треки, диапазоны секторов, сервометки и даже зоны. Это особенно важно для дисков с исходно низким качеством поверхности: при большом количестве дефектов (несколько миллионов) «утрамбовывание» их всех в дефект-листы по одному сделает работу системы трансляции слишком громоздкой и может привести к ошибкам. Если же убрать из трансляции целый трек (а это, для некоторых дисков и зон, десятки тысяч секторов), то в дефект-лист попадает не несколько тысяч, а одна запись, и транслятор будет работать гораздо надежнее и оперативнее.
Отдельно следует сказать о том, какой может быть система трансляции. Наиболее широкое распространение получили три типа транслятора: статический, динамический и многоуровневый. Работа статического транслятора обеспечивается особым модулем служебной информации; грубо говоря, все таблицы трансляции поверхности у такого накопителя уже построены и каждый раз загружаются из готового модуля транслятора из служебной зоны. Динамический транслятор работает по другому принципу: таблицы трансляции накопителя строятся в его памяти при каждом его старте с использованием имеющихся таблиц дефектов; отдельно модуля транслятора в служебной зоне таких накопителей нет. Наконец, многоуровневый транслятор подразумевает работу в накопителе нескольких систем трансляции (первого уровня, второго уровня и т.п.), при этом транслятор первого уровня обычно отвечает за физическую систему трансляции, а второго – за логическую. Многоуровневый транслятор разработан для обеспечения высокой скорости уничтожения данных: в случае необходимости одна из таблиц трансляции просто обнуляется (упрощенно при любом запросе диск отдает один и тот же сектор, заполненный нулями).
P-List, G-List и прочая
Непосредственно с дефект-менеджментом связаны таблицы дефектов (дефект-листы). Наиболее известными являются P-List и G-List (заводская и растущая таблицы дефектов); кроме них, в зависимости от производителя, могут иметься и таблицы других дефектов: треков (T-List), серво-разметки (S-List) и пр. Таблицы дефектов хранят в приемлемом для накопителя виде записи о бэд-блоках. Как правило, эти записи включают в себя физический адрес первого дефектного сектора и длину дефектной области (если это один сектор – то, соответственно, длина будет 1).
Потеря некоторых из этих таблиц может привести к недоступности данных пользователя, это крайне важно понимать.
Как проявляют себя диски с дефектами поверхности?
Дефекты поверхности диска – это, прежде всего, невозможность считать какую-то его область. Следовательно, при попытке чтения этой области проблемы с чтением будут сразу же заметны. Файл, который вы пытаетесь прочитать, не будет читаться; данные, которые вы будете пытаться скопировать, не будут копироваться; и т.д. В системе это обычно сопровождается сообщением типа «A read/write error has been detected» или подобной; если для копирования данных вы пользуетесь файловым менеджером, то вы увидите сообщение типа «Невозможно скопировать файл. Невозможно произвести чтение с диска или устройства».
Если область с бэд-блоками попала на какие-то установленные программы, то они либо перестанут запускаться вообще, либо их запуск будет затруднен, либо работа самой программы начнет завершаться с ошибками.
Ну и, наконец, если дефектная область попала на критически важные файлы операционной системы, та перестанет запускаться (как примеры: бесконечный первый экран Windows или «синий экран смерти» с характерными для проблем с жестким диском кодами ошибок: 0x00000010, 0x00000019, 0x00000022, 0x00000026, 0x0000004C, 0x00000051, 0x00000052, 0x00000068, 0x00000073, 0х00000077, 0х0000007А, 0х0000007В, 0х0000009В, 0х000000ED, 0x000000F4, 0xC0000135, 0xC0000218).
В областях с проблемами чтения (сильное замедление доступа к данным в секторе) система может подвисать (фризы), иногда – довольно надолго. Как пример: у вас имеется Word-документ, с которым вам нужно работать. Вы кликаете на этот файл, начинается запуск MS Word, и он продолжается значительно дольше обычного (десятки секунд или даже минуты). Это говорит о том, что медленно читаются сектора либо части программного обеспечения MS Word, либо – в самом документе.
Замедления еще не являются дефектными секторами, но их наличие – четкий сигнал к тому, что вам совершенно необходимо резервное копирование данных и, возможно, замена жесткого диска.
SMART и его атрибуты: как определить, что состояние поверхности критическое?
Для контроля за состоянием диска разработана подсистема микропрограммы, имеющая название SMART (Self Montoring, Analysis and Reporting Technology; технология самомониторинга, анализа и предупреждения). Эта подсистема работает независимо от других частей микропрограммы (хотя в некоторых современных дисках это не так и приводит к проблемам, но это – тема для отдельной статьи), ее работу можно упрощенно описать следующей схемой:
1) В подсистеме выделяются несколько характеристик (которые названы «атрибуты SMART»);
2) По выделенным атрибутам производится сбор «сырых» данных;
3) Собранные «сырые» данные анализируются микропрограммой, в результате этого анализа генерируется число (текущее значение атрибута);
4) На основании комбинации значений атрибутов формируется ответ на вопрос о текущем состоянии диска (Good, OK, Must be replaced и т.п.).
Обычно атрибуты SMART читаются из дисков при старте компьютера, и если с диском начинаются проблемы, Вы узнаете об этом еще до запуска Windows по сообщению примерно такого содержания: Hard Drive SATA0: SMART status BAD. Это означает, что по сумме атрибутов или даже по единственному из них диск «просел» до критических значений и более не может считаться исправным. В таких случаях рекомендуется произвести резервное копирование данных и замену накопителя.
Атрибуты SMART может читать не только операционная система, но и специальные программы, наиболее известные из которых: Victoria for Windows, Hard Disk Sentinel и т.п. Мониторя изменение атрибутов SMART, вы можете примерно предсказать, сколько еще времени отпущено вашему устройству. Например, наблюдая за атрибутом “Relocated sectors count” (счетчик переназначенных секторов; упрощенно – количество записей растущего списка дефектов), вы будете видеть, сколько секторов в день у вашего диска из нормальных превращается в плохие. Наблюдать, однако, я рекомендую не за отдельными атрибутами, а за их комплексом, и причина проста: например, у вашего диска начнет расти атрибут «Spin errors» (или подобный) – это означает, что диск не смог раскрутить шпиндельный двигатель. Как результат – при попытке очередной раскрутки может произойти сбой и головки спровоцируют возникновение дефектного сектора или, еще хуже – застрянут на поверхности. Если же вы вовремя заметили начало роста этого атрибута, то и меры для исправления ситуации с ним тоже примете вовремя: поменяете шлейфы (это наиболее частая причина возникновения таких ошибок) или блок питания.
Для примера приведу анализ нового SSD (ADATA SU800 емкостью 512 Гбайт) и бывшего в употреблении около полугода HDD Seagate Mobile HDD 2 Тбайт. Как мы видим, у SSD прекрасный SMART и график чтения без единой ошибки. А вот с HDD все достаточно грустно: уже есть дефекты, около половины атрибутов SMART уже в желтой зоне, и один атрибут (как раз отвечающий за бэд блоки) – в красной зоне. Данные необходимо резервировать, а накопитель или ремонтировать, или менять.
Состояние SMART твердотельного диска ADATA SU800 емкостью 512 Гбайт Состояние поверхности твердотельного диска ADATA SU800 емкостью 512 Гбайт Состояние SMART жесткого диска Seagate Mobile HDD емкостью 2 Тбайт Дефект поверхности жесткого диска Seagate Mobile HDD емкостью 2 Тбайт
Тестируем на бэд-блоки
Я рекомендую периодически (один раз в 2 – 3 недели) проводить проверку ваших носителей на дефектные сектора. Оптимально делать это следующим образом:
1) Скачать из интернета образ загрузочной флешки (часто называется Live CD), в состав которого входит программа для тестирования дисков (обычно это Victoria);
2) Записать скачанный образ на флешку (я использую для этого программу Rufus);
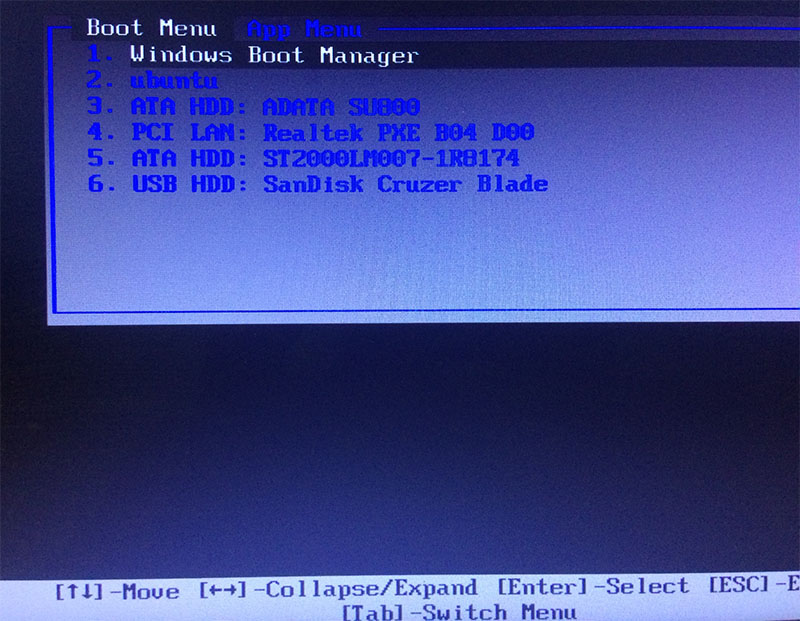
3) Загрузить ваш компьютер с записанной флешки (указав при загрузке компьютера в качестве загрузочного устройства вашу флешку – это достаточно просто, при запуске на одном из первых экранов вы увидите фразу типа «Boot options – F10” или подобную. Жмите на соответствующую кнопку, и у вас появится меню с возможностью выбора загрузочного устройства.
Экран загрузки, на котором указана функциональная клавиша для активации загрузочного меню Загрузочное меню компьютера, вызванное соответствующей функциональной клавишей
4) После загрузки – запускайте программу для проверки и проверяйте диск на дефекты. Внимание! Важно! При выборе теста никогда не отмечайте галку «запись» — это сотрет все ваши данные. Наилучшим режимом проверки является верификация (verify).
Возможно два варианта – либо вы не обнаружите на диске дефектов, либо – обнаружите. Если обнаружились дефекты, то вам нужно оценить следующие показатели:
1) Сколько нашлось дефектов?
2) К каким типам ошибок относятся дефекты?
3) Как расположены дефекты?
Если дефектов немного (до 100 штук) – то волноваться не стоит и, скорее всего, после описываемых ниже процедур ваш диск продолжит трудиться. Если дефектов много (свыше 100) – скорее всего, диск требует замены. Значение 100 в данном контексте не стоит воспринимать как приговор для диска – все сильно зависит от его объема и условий эксплуатации. Но в любом случае, если количество обнаруженных дефектов многократно превышает 100, диск подходит (если уже не подошел) к своей последней черте.
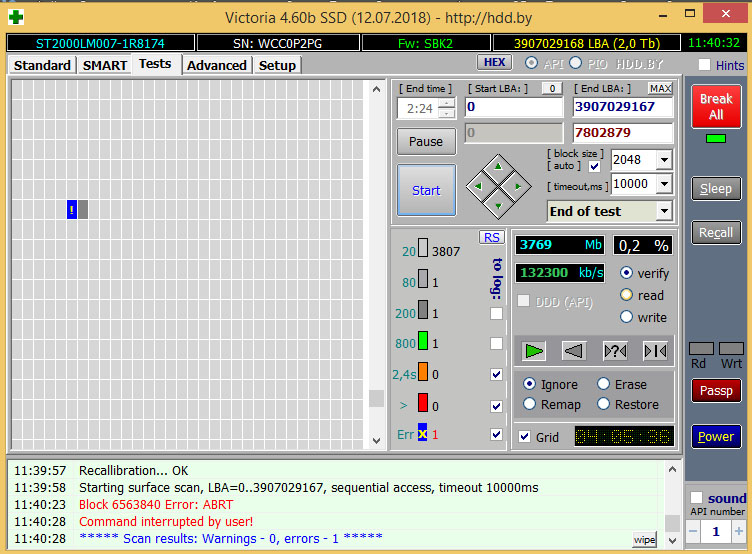
По типам ошибок наиболее распространены ABR (Abort, Command Aborted) – команда, которую получил диск при обращении к сектору, отвергнута; UNC (Uncorrectable ECC Error) – при чтении диска обнаружена нескорректированная ошибка данных (обычно контрольной суммы сектора); INF (Sector ID Not Found) – не удалось обнаружить идентификатор сектора. Все остальные ошибки встречаются реже и останавливаться на их обсуждении мы не будем. О чем же говорят нам эти ошибки? Если при чтении сектора отвергнута команда, то наиболее вероятная причина этого – ошибка микропрограммы (например, «зависшие» операции журналирования SMART). Скорее всего, при повторном тестировании такой ошибки или не появится вообще, или она выскочит в другом месте.
Ошибки типа INF говорят о тяжелых повреждениях поверхности, связанных с разрушением сервисной информации поверхности (или заголовок сектора, или (чаще) заголовок трека). При обнаружении ошибок такого типа я настоятельно рекомендую подумать о срочной замене накопителя и немедленном резервировании данных. Разрушение поверхности – абсолютно непредсказуемое явление, один диск может прожить с широкой царапиной несколько лет, а другой от почти невидимого следа удара полностью запилиться за пару секунд.
Наконец, ошибки типа UNC могут возникать и как результат аппаратных проблем (непосредственные проблемы с поверхностью), и как результат неправильной работы программ (например, при записи данных не финализирована контрольная сумма сектора). Такие ошибки чаще всего легко «лечатся» и диск продолжает нормально работать годами.
И последнее – это то, как дефекты расположены. Скопления по несколько десятков или сотен дефектов должны вас насторожить – возможно, это небольшая царапина, которая вполне может превратиться в запил. Если дефекты расположены поодиночке, поводов для беспокойства меньше.
Что делать, если обнаружены дефектные сектора?
Первый, и наиболее правильный совет – не паниковать.
Определитесь, имеются ли на вашем начавшем «сыпаться» диске нужные вам данные. Если они есть – немедленно приступите к их резервированию. Любые действия с диском, которые будут описаны ниже, можно проводить только после того, как у вас появится полная резервная копия ваших данных.
Итак, данные зарезервированы. Проверьте еще раз, что вы скопировали в резерв именно те файлы, которые нужны, а также то, что эти файлы работают. Если все нормально, то можно приступать к процедуре лечения диска от дефектных секторов.
Образование дефектов – это нормально. Жесткий или твердотельный диск устроен таким образом, что новообразующиеся дефектные сектора по мере их обнаружения будут скрыты средствами самого накопителя. Если вы обнаружили 1 – 2 бэд-блока, то, скорее всего, накопителю просто не хватило времени на их «ремонт» (скажем, диск обнаружил дефектный сектор и уже собирался приступить к его замещению, как вы выключили компьютер). Вот этот вот принцип (автоматического скрытия дефектного сектора при его обнаружении) мы и будем использовать для лечения диска.
Поменяйте шлейфы (и SATA, и питание) – часто ошибки образуются по причине плохого контакта (любой разъем имеет свойство расшатываться, контакт – ухудшаться). Это обезопасит вас от образования новых программных дефектов и продлит жизнь вашего диска.
Выше я уже описывал, как создать загрузочную флешку для запуска тестирования жесткого диска на выявление дефектов. Нам нужно будет снова использовать эту флешку.
Загружаемся с флешки и запускаем программу для тестирования носителей информации (обычно это Victoria). И теперь начинается самое интересное – лечение. Для того, чтобы излечить диск от дефектов, мы используем только механизмы, заложенные в сам накопитель: программные бэд-блоки (так называемые софт-бэды) уберутся, когда у сектора появится правильная контрольная сумма, а реальные дефекты мы попробуем заставить диск убрать автоматически. Обоих зайцев будем убивать записью.
Настоятельно рекомендую еще раз убедиться в том, что все нужные данные были зарезервированы – после того, как мы прогоним диску запись, данных на нем не будет. Если все хорошо и вы уверены, что все ваши данные надежно сохранены на другом носителе – приступаем к лечению. Для этого в Victoria, после выбора нужного диска, переходим на вкладку тестов и выбираем write (запись). Внимание! Данный тест полностью и безвозвратно стирает данные на физическом уровне!
Нажимаем Start и ждем окончания теста. После того, как он завершился, во вкладке тестов выбираем верификацию (verify) и снова нажимаем Start. После окончания верификации оцениваем график чтения. Он должен стать ровнее, дефекты должны исчезнуть. Если этого не произошло – можно попробовать пройтись записью еще один – два раза. Как правило, в случае с софт-бэдами и небольшим количеством новообразовавшихся дефектов достаточно одного прохода записью. Если их нужно больше – значит, диск работает уже на пределе своих возможностей и остро нуждается в замене. Подумайте, захотите ли вы доверять данные такому накопителю.
Почему я советую провести процедуру лечения записью прежде, чем ставить на диске крест? Если проблемы крылись в программных ошибках или в плохом контакте (расшатанные разъемы, плохое качество шлейфов и т.п.), то замена разъемов/шлейфов и запись их полностью излечит и поверхность диска станет как новая. По нашей статистике не меньше половины дисков с бэд-блоками – это диски, имеющие софт-бэды, с прекрасной (на самом деле) поверхностью. «Заваленный» SMART, провалы в графиках чтения и прочие прелести казалось бы умирающего диска – лишь следствие плохого контакта и программных ошибок, аппаратно диск может быть еще весьма и весьма далек от путешествия в свой битовый рай. Ну а если его можно спасти малой ценой (по два доллара за шлейфы хорошего качества и ночь работы компьютера в режиме записи и верификации) – то почему бы и нет?
Заключение
Как я уже писал выше, образование на диске дефектных секторов — нормальное явление при эксплуатации любого носителя информации, и их микропрограмма приспособлена для того, чтобы в автоматическом режиме решать эту проблему. Поэтому при обнаружении нескольких дефектов особых поводов для беспокойства нет — как только диск их обнаружит, он с ними самостоятельно справится. Если дефектов обнаружилось много, это может уже быть серьезно, и в этом случае я настоятельно рекомендую начать с резервного копирования данных, после которого пробовать описанный выше механизм лечения. Если же он не помог — не пытайтесь использовать диск, «обходя» дефектные области с помощью создания разделов разного размера и расположения. Диск нужно менять — риск того, что дефектная область будет увеличиваться, очень велик, при современных ценах на накопители есть ли смысл так рисковать?
Оснащение лаборатории восстановления данных – дело, которое должно производиться на постоянной основе. Один из важных моментов – это приобретение различных адаптеров и переходников, позволяющих подключить к нашему оборудованию любое устройство. Этому мы уделяем постоянное внимание, отслеживая появление новых устройств, новых типов соединений, новых стандартов. В нашей лаборатории имеется два важных списка: входящие соединения и имеющиеся соединения.
Входящие соединения – это спиcок, в который включаются все перспективные типы коннекторов, на которые нам нужно приобрести адаптер или переходник. Недавно в него добавился новый коннектор для SSD дисков – NF1. Пока ни один производитель не предлагает такого адаптера, но как только он появится в продаже, мы его немедленно приобретем.
Имеющиеся соединения – это те типы адаптеров и переходников, которые уже приобретены для нашей лаборатории. Как вы можете видеть на фотографиях, каждый адаптер или переходник должным образом промаркирован, и мы точно знаем, с каким устройством и какой переходник нам использовать.
В чем преимущество использования переходников? Почему мы уделяем этому так много внимания и инвестируем в это наши средства?
Все очень просто. Конечно, можно взять спецификацию коннектора и, припаяв необходимые провода, создать временное соединение для вычитывания данных. Однако у такого метода работы есть четыре очень важных минуса:
1) Возможность совершить ошибку и, как результат, электрически сжечь устройство. От ошибок не застрахован абсолютно никто, и их происхождение бывает различным, начиная от банальной невнимательности (к примеру, когда специалиста отвлекли во время работы) и заканчивая неправильной интерпретацией цвета провода (так, я припаял сюда коричневый провод, значит, и сюда нужно коричневый; а по факту у вас темно-коричневый и светло-коричневый проводники, и перепутав их, вместо 5 вольт вы подали на схему 12 – итог плачевен).
2) Паразитные токи. При работе с проводниками большой длины (а для современных высокочастотных соединений большой длиной может оказаться уже 5 – 6 см) возникают паразитные токи, которые будут искажать проходящие сигналы и продуцировать ошибки. Это неизбежно приведет к неправильной интерпретации приходящих на интерфейс данных и, как следствие – к большому количеству некорректируемых ошибок. При этом само устройство будет работать прекрасно и ошибок продуцировать не будет.
3) Малая оперативность. Для организации соединения напайкой проводников требуется время, иногда – довольно значительное, что негативно сказывается на общем времени проведения работ. Среднее время, за которое специалист, не знакомый со спецификациями коннектора, может организовать соединение методом напайки проводников, составляет примерно 1 – 2 часа. При использовании адаптера время организации соединения составит 10 – 15 секунд. И нам не придется каждый раз тратить драгоценное время для того, чтобы напаяться на разъем и получить доступ к данным, мы сделаем это быстро, безопасно и очень качественно.
4) Гарантийный обмен. Следы пайки, конечно, можно скрыть, особенно если паяет профессионал. Но скрыть их полностью все равно не получится, и дотошный гарантийный отдел их обязательно увидит и гарантированно откажет вам в гарантии (простите за каламбур). Другое дело – адаптер. Вы включаете накопитель в его штатный разъем, без каких-либо изменений для самого устройства, и совершенно спокойно, после завершения всех работ, можете обменять его по гарантии.
Уничтожение данных – важная проблема современного IT-сообщества. Ситуации, при которых может потребоваться полное и безвозвратное уничтожение данных, различны, и не будут нами здесь обсуждаться. Мы поговорим о том, как можно уничтожить данные с различных типов носителей.
1. Флеш-накопители
В различных флеш-накопителях носителем информации является чип флеш-памяти, или несколько таких чипов. Как правило, они работают под управлением контроллера – микросхемы, организующей логическое транслирование банков и страниц памяти для оперционной системы. Надежно уничтожить данные с флеш-накопителя возможно следующими способами
— Стирание накопителя. Физически реализуется как запись определенного паттерна в каждый сектор такого носителя. При этом восстановление данных абсолютно невозможно. Реализовать можно как коммерческим, так и свободно распространяемым ПО (MHDD, Victoria и т.д.) для тестирования накопителей данных.
— Термическое воздействие на чип памяти. Микросхемы флеш-памяти весьма чувствительны к воздействию высоких температур. При нагревании их до 370° С в течение 2 минут внутри таких микросхем могут появляться bad blocks (нечитаемые сектора), нагревание до 400° С в течение 2 минут обязательно приведет к появлению таких секторов, нагревание свыше 500°С за тот же период времени может разрушить уже значительную часть секторов (а следовательно, и данных). Сжигание, таким образом, надежно уничтожит данные с такого устройства.
— Микроволновая деструкция. Чипы памяти флеш-устройств включают в себя большое число металлических элементов. Помещение их в интенсивное микроволновое излучение приведет к многочисленным разрушениям этих элементов, что сделает чип памяти абсолютно непригодным к эксплуатации. Оптимальным вариантом такого уничтожения данных являются направленные микроволновые излучатели, однако можно использовать и обычную бытовую микроволновую печь – при этом вы должны осознавать, что последняя может выйти из строя в результате ваших экспериментов.
— Механическое разрушение. Возможно, как и для любого другого устройства. Однако не всегда применимо в силу того, что требуется достаточно сильное механическое воздействие для того, чтобы физически разрушить чип памяти.
Мгновенное и гарантированное разрушение данных с флеш-устройств возможно только с использованием микроволнового излучения. Все остальные методы требуют определенного времени.
2. Оптические носители
Оптические носители (CD, DVD, BD) – один из самых удобных вариантов для уничтожения данных, так как имеют определенное количество слабых мест, делающих уничтожение данных быстрой и дешевой процедурой.
— Механическое разрушение. Возможно как просто переломить диск пополам (практически моментально; однако при этом возникает риск того, что диск лопнет, и от него отлетят осколки, которые могут вас ранить, поэтому настоятельно рекомендую ломать диски в защитных перчатках или рукавицах и с защитными очками на глазах), так и зацарапать его снизу (со стороны подложки; метод не слишком надежен, так как данные при этом не уничтожаются, после полировки зацарапанной поверхности их можно снова считать) или сверху (гарантированное уничтожение данных, так как царапая диск сверху, вы уничтожаете слой, несущий данные).
— Термическое воздействие. Оптические носители сделаны из легко плавящегося и горючего пластика. Нагревая их, мы надежно уничтожаем данные.
— Чувствительность к агрессивным веществам. Кислоты и щелочи, а также обычные органические растворители (ацетон, этилацетат и т.п.) крайне негативно воздействуют на пластик, из которого делаются оптические носители – вплоть до полного его растворения. Естественно, данные после такого воздействия восстановить уже не получится.
3. Дискеты
Едва ли не самые слабые в отношении надежности носители информации. Уничтожение данных с них не представляет никакого труда
— Стирание накопителя. Заполнение всех его секторов определенным паттерном. Возможно при помощи свободно-распространяемого ПО (Victoria и т.п.).
— Механическое разрушение носителя информации. Любая дискета – это пластиковый диск с магнитным напылением, заключенный в пластиковый же корпус. Достаточно легкого механического воздействия, чтобы разрушить корпус и извлечь магнитный диск, который можно порвать, после чего считать с него данные будет уже невозможно.
— Температурные воздействия. Пластик корпуса и магнитного диска дискеты горюч и плавок. Достаточно кратковременного воздействия высокими температурами для того, чтобы магнитный носитель расплавился или размагнитился.
— Агрессивные среды. Любой сильный растворитель (ацетон, эфир, хлороформ, этилацетат и т.п.) полностью разрушит магнитный носитель в дискете за считанные секунды. То же самое относится и к кислотам.
— Размагничивание. Возможно с использованием как специализированных устройств (дегауссеров), так и посредством обычного (но достаточно сильного) магнита.
4. Накопители на жестких магнитных дисках (НЖМД)
Наиболее распространенный тип носителей информации. Уничтожение данных возможно как стиранием с использованием специализированного ПО, так и различными типами механического воздействия.
— Стирание. Реализуется несколькими способами. Наиболее распространенным способом является запись определенного паттерна в сектора накопителя с использованием специализированного ПО (MHDD, Victoria и т.п.). Меньше распространено стирание накопителей посредством команды Security Erase, поддерживаемой всеми без исключения НЖМД. Основной недостаток такого способа уничтожения данных – для накопителей большой емкости оно займет немало времени (до нескольких часов).
— Физическое разрушение пластин. Обычно реализуется посредством пробивания накопителя металлическим штырем или просверливания накопителя насквозь.
— Физическое разрушение накопителя сильным ударом во время работы накопителя. Как правило, приводит к незамедлительному смещению осей шпинделя и БМГ и к полному или частичному разрушению внутренних узлов НЖМД. Достоинство: очень быстрый способ уничтожения данных. Недостаток: не является абсолютно надежным методом уничтожения данных, накопитель может пережить даже очень сильное механическое воздействие (хотя это случается и не часто).
— Полное размагничивание накопителя. Осуществляется посредством специальных машин (дегауссеров), подающих на накопитель сильный магнитный импульс. Происходит полное размагничивание пластин с полной потерей служебной и пользовательской информации.
— Термическое воздействие (нагревание). При определенной температуре нагревания ферромагнетики теряют магнитные свойства, данные полностью теряются. Недостатком является необходимость нагреть накопитель достаточно сильно: накопитель необходимо прогреть, так как пластины расположены внутри гермоблока в воздушной среде. Этого нельзя сделать быстро.
Таким образом, наиболее быстрыми и недорогими способами уничтожения данных с современных накопителей являются: размагничивание дегауссером (НЖМД; применимо также и для дискет) и механическое разрушение. Например, в одной из российских компаний имелся специально нанятый охранник с боевым пистолетом, единственной функцией которого было сделать несколько выстрелов в черный кружок, нарисованный на корпусе сервера; за этим кружком располагались НЖМД – таким образом, выстрелы должны были разрушить накопители и сделать невозможным восстановление с них данных. Можно сказать, что такой способ удаления данных достаточно экзотичен, хотя по тому же принципу организованы механические устройства уничтожения данных на базе пиропатрона, осуществляющего при детонации резкий удар по НЖМД посредством заостренного металлического штыря.
Естественно, что после уничтожения данных таким образом использование самого устройства становится невозможным: устройство физически разрушается. Если вы планируете использовать устройство после уничтожения данных, наиболее правильным будет стирание.
Наша компания оказывает услуги по профессиональному уничтожению данных с любых типов носителей любым способом.
Не так давно корпорация Seagate объявила о создании новой, революционной технологии защиты данных от несанкционированного использования: ISE (Instant Secure Erase – немедленное защищенное стирание) (кстати, технологию подхватила и компания HGST – а значит, Western Digital; другими словами, моментально стирающийся диск сейчас можно купить у любого производителя). Вкратце суть технологии заключается в следующем: диск шифруется от начала и до конца аппаратно, для расшифровки применяется некий ключ. В случае необходимости вы меняете ключи шифрования (что называется, «легким движением руки») – и ваш диск оказывается намертво зашифрованным, так как старые ключи уже отсутствуют, а данные зашифрованы именно ими. После того, как накопитель начнет перешифровывать данные (а шифрование идет посекторно) с использованием нового ключа, данные превратятся в кашу, восстановить которую будет уже невозможно. Данная технология может быть использована только для накопителей, которые поддерживают Seagate Self-Encryption (само-шифрование) или непосредственно технологию ISE.
Для чего это сделано? Шифрование – это новая «фишка» в индустрии накопителей данных. Это фишка, направленная на «безопасность данных»: клиенту нравится, что его данные зашифрованы, что только он, в случае чего, может гарантированно получить к ним доступ. Если, не дай Бог, его компьютер украдут – просмотреть его данные никто не сможет. Это греет душу клиента, вселяет в него уверенность, что все его персональные тайны так и останутся тайнами.
Увы, покупая такой замечательный накопитель, вы приобретаете бомбу замедленного действия. Никто не может гарантировать вам, что устройство хранения информации не умрет однажды, похоронив все, что на нем записано. Да, производители обещают бешеные сроки наработки на отказ (для некоторых моделей накопителей до 10 млн. часов), однако кто вам сказал, что эти сроки относятся к конкретному, купленному вами, устройству? В принципе, ему даже не обязательно умирать своей смертью: вы можете его уронить, утопить, подать на него слишком много электроэнергии (или за вас это сделает молния, или энергетическая компания, или наэлектризованный кот потрется об устройство и прибъет важные микросхемы статическим электричеством, или…), сесть на него, и т.п., и т.д. Страшно? А то. К нам постоянно обращаются с накопителями, которые погибли не от старости.
Но мы не об этом. Технология ISE не даст доступа к данным, если пользователь не будет авторизован. Предусмотрено несколько способов авторизации, наиболее простой из которых – пароль (есть и более экзотические возможности, среди которых – сканирование отпечатков пальцев и сетчатки глаза; но это для совсем уж параноиков). В случае необходимости пользователь буквально двумя нажатиями мыши полностью уничтожит данные – и после этого их будет уже невозможно восстановить.
Возникает закономерный вопрос – а что делать, если та самая смертельная для данных комбинация набрана случайно? Если пользователь ткнул мышкой не туда и активировал процесс ISE? Если забыл пароль? Есть ли в этой системе «защита от дурака»?
Нет, такой защиты нет. При работе с данными подразумевается наивысший уровень защиты. Поэтому, имея в использовании ISE диск, будьте предельно аккуратны и помните, что уничтожить ваши данные теперь еще проще и еще быстрее, чем раньше. А вытащить их обратно возможно только в очень крупных компаниях по восстановлению данных или в профильных спецслужбах.
Третье – вы можете легко перемещать диски внутри BeyondRAID массива без каких-либо изменений в его работе и данных. Такое просто невозможно для традиционных RAID – если вы поменяете местами два диска, RAID перестанет существовать. Для чего это сделано? К примеру, вам нужно переместиться в другую страну или город. Зачем везти с собой весь NAS, если можно просто взять с собой диски, а там, на новом месте, вставить их в другой Drobo, и все заработает? Да, все так: вы можете переставлять диски из одного Drobo в другой, в произвольном порядке, и все будет работать. Фантастика, не так ли?
Относительно недавно компания Drobo анонсировала новое устройство на базе разработанной ей технологии BeyondRAID – Drobo 5N2 NAS. NAS, как мы помним – это сетевой накопитель (Network Attached Storage), цифра 5 в названии означает количество портов, а цифра 2 после N – второе поколение (есть еще просто 5N, более старая модель). И вот он уже продается…
Компания Drobo в этом продукте объединила корпоративные решения (такие, как BeuondRAID) с решениями бюджетного класса, расширила порог емкости подключаемых дисков (теперь общий объем хранилища NAS Drobo 5N2 может достигать 64 ТБ – совершенно фантастическая величина, недоступная пока для NAS-устройств других производителей, за исключением Apple), значительно упростила управляющий интерфейс. Использование усовершенствованного процессора, нового поколения микропрограммы и управляющего программного обеспечения позволило Drobo значительно повысить быстродействие сетевого хранилища; кроме того, предоставлен совершенно новый уровень общего использования сетевого хранилища, удаленного копирования и резервирования данных и аварийного восстановления. Как отмечает компания Drobo, это устройство является самым простым в использовании NAS на рынке.
Основное преимущество любого продукта Drobo – это технология BeyondRAID, которую эти продукты используют. Технология дает многочисленные преимущества, такие как: переход с одного уровня защиты данных на другой (скажем, с использования для контроля четности одного диска – на использование двух) простым кликом мышки; простое добавление диска в систему без видимого глазу замедления в работе при перестроении (rebuild) массива; уменьшение риска потери данных при отказе одного или нескольких дисков; и т.п.
Чем же отличается BeyondRAID от «обычных» типов массивов?
Первое – вы можете использовать диски разного размера, и они будут задействованы полностью. Если в обычном RAID-массиве вы можете использовать только диски одного размера, или диски разного размера – но в этом случае они будут группироваться в свои собственные мини-массивы либо будут использоваться не полностью – то технология BeyondRAID дает вам возможность использовать любой диск на всю его емкость совершенно без каких-либо условий или ограничений.
Второе – это «виртуальная горячая замена». Технология BeyondRAID на пользовательском уровне оперирует не жесткими дисками (в традиционном RAID-массиве, при выходе из строя одного диска, будет автоматически подключен диск горячей замены, если он предусмотрен в системе, после чего массив будет перестроен, и начнет работать нормально; на время подключения диска горячей замены и перестроения массива он не защищен от сбоев, и если в это время что-то произойдет с другим диском – то массив перестанет существовать), а свободным местом. Если свободного места в массиве BeyondRAID больше, чем емкость вышедшего из строя накопителя, массив будет перестроен и продолжит нормальную работу без видимых для пользователя замедлений. Именно поэтому использование технологии Drobo BeyondRAID дает возможность компании Drobo утверждать о большем уровне защиты данных пользователя, чем в традиционных массивах – ведь пока в Drobo есть свободное место, большее, чем выходящие из строя диски, массив будет жить. Простой пример: если у вас 5-портовый NAS Drobo 5N2, в котором установлено 5 дисков: 500 ГБ, 500 ГБ, 2 ТБ, 1 ТБ, 12 ТБ и вы используете 4 ТБ из всей этой емкости, ваш массив будет нормально работать, даже если выйдут из строя все 4 первых диска. Правда, если выйдет из строя последний диск, то для массива это уже будет невосполнимой утратой – именно поэтому, не смотря на то, что в сетевых хранилищах Drobo можно использовать диски разной емкости – использование одинаковых дисков все-таки предпочтительнее.
Третье – вы можете легко перемещать диски внутри BeyondRAID массива без каких-либо изменений в его работе и данных. Такое просто невозможно для традиционных RAID – если вы поменяете местами два диска, RAID перестанет существовать. Для чего это сделано? К примеру, вам нужно переместиться в другую страну или город. Зачем везти с собой весь NAS, если можно просто взять с собой диски, а там, на новом месте, вставить их в другой Drobo, и все заработает? Да, все так: вы можете переставлять диски из одного Drobo в другой, в произвольном порядке, и все будет работать. Фантастика, не так ли?
Четвертое – два уровня защиты. Drobo BeyondRAID – единственный тип массива, в котором реализовано два уровня защиты данных: при потере одного диска и при потере двух дисков. Вы можете легко переключиться между этими уровнями в управляющем модуле ПО Drobo. И не забывайте, что кроме двухуровневой защиты, BeyondRAID имеет еще и механизм «виртуальная горячая замена», о котором я говорил выше. Защита BeyondRAID осуществляется посредством введения технологии “disk pack”, которая, в отличие от “RAID group” или “disk pool” в традиционных RAID-массивах, не разграничивает диски на физическом уровне, а рассматривает их все как единый диск; при таком подходе к виртуализации дискового пространства извлечение из дискового массива одного или нескольких дисков означает лишь уменьшшение емкости всего дискового пакета и полную или частичную (в зависимости от оставшегося после извлечения из пакета диска) потерю надежности массива в виде потери некоторой доли или всей его избыточности (redundancy). Данные при этом никак не страдают (если, конечно, из дискового пакета не извлечено дисков больше, чем имелось в массиве свободного места; в этом случае потери данных неизбежны, так как виртуальная горячая замена уже работать не будет, и физически извлекается часть данных).
Ну а теперь о том, как же это работает. В отличие от стандартных типов RAID, использующих порции данных (stripe), равномерно и циклично распределенных на всех дисках массива (включая порции данных, обеспечивающих восстановление – XOR), BeyondRAID использует зоны. Зона формируется как несколько регионов разных дисков для обеспечения максимальной емкостной и защитной эффективности. Выглядит это примерно так:
Соответственно, даже при использовании в сетевом хранилище Drobo одного диска, устройство автоматически делает на нем две полностью идентичные зоны. Это не дает защиты от выхода из строя массива в случае поломки диска, так как диск – один, однако это значительно повышает шансы на выживаемость данных, если на диске начинают появляться дефектные сектора.
Ну а теперь о грустном. Как обстоят дела с восстановлением данных с сетевых хранилищ Drobo? Все отнюдь не так радужно, как в случае с обычными RAID-массивами. И причиной тому, конечно же, пресловутый и такой классный BeyondRAID. Пока выходящие из строя диски массива могут быть компенсированы встроенными в NAS технологиями защиты данных и автоматического исправления проблем – все прекрасно. Но как только условия для использования этих технологий прекращаются, массив перестает существовать. С учетом того, что в массиве в силу его организации существует несколько, назовем их виртуальными, структур (зоны и сам дисковый пакет), к нему неприменимы стандартные для RAID средства восстановления данных: поиск циклической конфигурации, порядка дисков и построение массива средствами различного ПО. В случае с Drobo информацию придется восстанавливать в полуавтоматическом режиме – то есть искать зоны вручную, собирать их образы, а затем уже из образов зон собирать сам дисковый пакет и вытаскивать из него данные. При этом нужно будет вначале найти, какие именно диски входили в пакет до того, как случилась фатальная неисправность, ведь если мы будем использовать для восстановления данных те диски, которые вышли из строя раньше, и после их выхода из строя дисковый пакет был перестроен с использованием технологии «виртуальная горячая замена» — массив был перестроен и данные на старых дисках уже не могут быть использованы для построения зон, так как порядок зон и их структура полностью поменялись. Поэтому восстановление данных с постепенно деградировавших массивов Drobo занимает много времени и имеет очень высокую стоимость.
Другое дело, если из строя вышел сам NAS, или все диски массива вышли из строя одновременно (например, в результате скачка напряжения). В первом случае нам достаточно извлечь из NAS-бокса исправные диски, вставить их в NAS той же модели – и, исходя из особенностей BeyondRAIID, массив должен «ожить», и мы снова получим данные в полном объеме. Во втором случае все несколько сложнее, но все же не так сложно, как собирать массив в полуавтоматическом режиме одну – три недели: достаточно привести в чувство диски массива, сделать их полные посекторные копии и установить в исправный Drobo NAS – после этого, опять же в силу спецификаций BeyondRAID, мы должны получить полный доступ ко всем данным.
В общем и целом, бесспорно, Drobo NAS – это прекрасное решение для тех, кто хочет получить надежное устройство и не думать о том, как его активировать и как им управлять – все, что вам нужно, это вставить в NAS диски, которые вы хотите в нем использовать, создать массив с нужным для вас типом надежности, и наслаждаться работой устройства. Однако я настоятельно рекомендую проверять время от времени, не вышел ли из строя какой-либо диск массива, и в случае обнаружения такого события (либо заглядывая время от времени в настройки хранилища через web-интерфейс, либо просматривая состояние передней панели устройства, где у каждого диска имеется led-индикатор, который в случае исправности устройства горит зеленым цветом, а неисправности – красным) «скормить» NAS-боксу другой, пустой, исправный диск вместо сломавшегося. Ну а если вы потеряли данные, хранящиеся на вашем Drobo, то мы в силах вернуть их обратно.
Довольно редкий на настоящее время диск – Western Digital Raptor с прозрачной крышкой. Предлагаю посмотреть, как ведет себя исправный и неисправный жесткий диск. У неисправного вышел из строя блок магнитных головок.
Исправный диск, как мы видим, раскручивает шпиндельный двигатель, распарковывает головки, а затем производит рекалибровку – последовательность операций чтения-записи, призванных проверить исправность блока магнитных головок и провести необходимые первоначальные калибровки. После того, как диск заканчивает рекалибровку, если к нему нет запросов, он возвращает головки в парковочную зону и ждет обращения.
Неисправный диск раскручивает шпиндель, распаковывает головки, но не может спозиционироваться на треке – поэтому рекалибровки не происходит, диск начинает двигать головками в поисках треков – это сопровождается мерным стуком. Такое поведение в зависимости от модели и производителя диска может быть либо коротким (несколько мерных ударов, затем головки уводятся в парковочную зону и, в зависимости от производителя и модели диска, либо диск продолжает вращаться, либо (чаще) останавливает шпиндельный двигатель и начинает «ждать», пока ему дадут дополнительные инструкции), либо долгим (иногда – до тех пор, пока диск не выключат). Связано это с особенностями работы прошивки диска: в одном случае в прошивке заложено строго заданное количество тестов (рекалибровок), и если они не завершились успехом – то производится остановка работы диска, в другом случае – в прошивке нет такого ограничения, и она будет пытаться искать треки и рекалиброваться, что называется, до победного конца.
Диагностика неисправностей жесткого диска по звуку – один из наиболее старых и действенных методов диагностики неисправностей этих устройств. Опытный специалист знает, как должно рекалиброваться то или иное устройство, если звуки из диска будут отличаться от эталонных, то по характеру звуков будет ставиться предварительный диагноз. Например, если жесткий диск даже не начинает рекалибровку (как говорят специалисты по восстановлению данных, «не цепляет серву»), а сразу уходит в мерный стук – скорее всего, вышла из строя микросхема коммутатора-предусилителя; если стук сопровождается шипящими звуками, как будто внутри гермоблока работает точилка для ножа – скорее всего, головки упали на поверхность и поверхность запиливается; если диск начинает рекалибровку, а затем уходит в стук – при этом время от времени делается новая попытка рекалибровки – то скорее всего либо неисправна микропрограмма, либо – одна из головок; и т.п.
Время от времени поступают заказы, когда нужно не просто спасти данные, а сделать полный клон исходного диска, включая название модели и серийный номер. Это нужно в тех случаях, когда диск трудился в каком-то станке или машине с цифровым управлением, гарантия на которую давно закончилась, а простой стоит немалых денег. Как правило, такие станки покупаются за рубежом, и вызывать соответствующего ремонтника намного дороже, чем восстановить работоспособность управляющего модуля (сиречь диска) на месте.
Как делаются такие клоны? Сначала мы вычитываем неисправный диск посекторно. После того, как диск вычитан, эта копия переносится на тот диск, который мы будем использовать для создания полного клона. Данные на такой диск также переносятся посекторно — то есть, мы получаем точную копию больного диска.
Читаем один WD 250 GB на другой такой же (подготовленный с помощью ПАК РС-3000, теперь он имеет такое же название модели и серийный номер); исходный диск из автономной метеорологической станции, система охладения которой вышла из строя и плата диска сгорела.
После того, как все сектора больного диска перенесены на здоровый накопитель, производится модификация микропрограммы будущего клона. Во-первых, изменяется его паспорт (название модели, серийный номер и емкость). Это можно сделать двумя способами: записать в будущий клон паспорт от неисправного диска, или изменить паспорт будущего донора, записав в него название модели, емкость и серийный номер больного.
В качестве донора для создания полного клона может использоваться, в принципе, любой диск. С помощью программно-аппаратного комплекса РС-3000 можно изменить паспорт любого из существующих жестких дисков. Кстати, емкость диска совсем не обязательно «закреплять» в паспорте — вполне можно обойтись механизмом HPA (Host Protected Area), который также позволяет ограничивать емкость диска. При использовании этого механизма полную емкость диска всегда можно вернуть без использования ПАК РС-3000 (если это, конечно, будет нужно).